 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelect, Extract and Generate: Neural Keyphrase Generation with Syntactic Guidance
Paper and Code

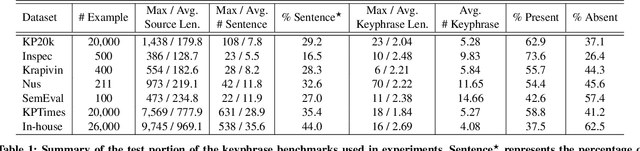


In recent years, deep neural sequence-to-sequence framework has demonstrated promising results in keyphrase generation. However, processing long documents using such deep neural networks requires high computational resources. To reduce the computational cost, the documents are typically truncated before given as inputs. As a result, the models may miss essential points conveyed in a document. Moreover, most of the existing methods are either extractive (identify important phrases from the document) or generative (generate phrases word by word), and hence they do not benefit from the advantages of both modeling techniques. To address these challenges, we propose \emph{SEG-Net}, a neural keyphrase generation model that is composed of two major components, (1) a selector that selects the salient sentences in a document, and (2) an extractor-generator that jointly extracts and generates keyphrases from the selected sentences. SEG-Net uses a self-attentive architecture, known as, \emph{Transformer} as the building block with a couple of uniqueness. First, SEG-Net incorporates a novel \emph{layer-wise} coverage attention to summarize most of the points discussed in the target document. Second, it uses an \emph{informed} copy attention mechanism to encourage focusing on different segments of the document during keyphrase extraction and generation. Besides, SEG-Net jointly learns keyphrase generation and their part-of-speech tag prediction, where the later provides syntactic supervision to the former. The experimental results on seven keyphrase generation benchmarks from scientific and web documents demonstrate that SEG-Net outperforms the state-of-the-art neural generative methods by a large margin in both domains.