 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmental Audio Word2Vec: Representing Utterances as Sequences of Vectors with Applications in Spoken Term Detection
Paper and Code
Aug 07, 2018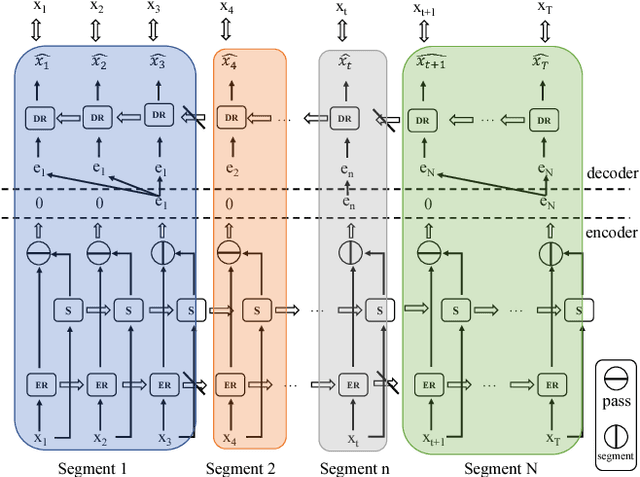

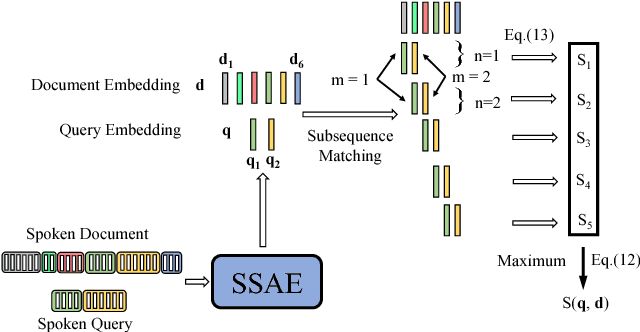
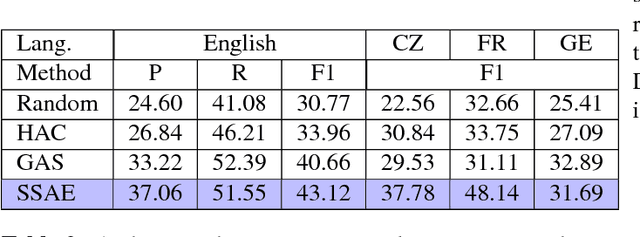
While Word2Vec represents words (in text) as vectors carrying semantic information, audio Word2Vec was shown to be able to represent signal segments of spoken words as vectors carrying phonetic structure information. Audio Word2Vec can be trained in an unsupervised way from an unlabeled corpus, except the word boundaries are needed. In this paper, we extend audio Word2Vec from word-level to utterance-level by proposing a new segmental audio Word2Vec, in which unsupervised spoken word boundary segmentation and audio Word2Vec are jointly learned and mutually enhanced, so an utterance can be directly represented as a sequence of vectors carrying phonetic structure information. This is achieved by a segmental sequence-to-sequence autoencoder (SSAE), in which a segmentation gate trained with reinforcement learning is inserted in the encoder. Experiments on English, Czech, French and German show very good performance in both unsupervised spoken word segmentation and spoken term detection applications (significantly better than frame-based DTW).