 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing is Knowing! Fact-based Visual Question Answering using Knowledge Graph Embeddings
Paper and Code


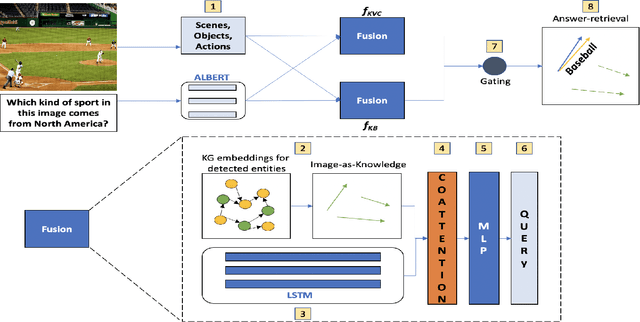

Fact-based Visual Question Answering (FVQA), a challenging variant of VQA, requires a QA-system to include facts from a diverse knowledge graph (KG) in its reasoning process to produce an answer. Large KGs, especially common-sense KGs, are known to be incomplete, i.e. not all non-existent facts are always incorrect. Therefore, being able to reason over incomplete KGs for QA is a critical requirement in real-world applications that has not been addressed extensively in the literature. We develop a novel QA architecture that allows us to reason over incomplete KGs, something current FVQA state-of-the-art (SOTA) approaches lack.We use KG Embeddings, a technique widely used for KG completion, for the downstream task of FVQA. We also employ a new image representation technique we call "Image-as-Knowledge" to enable this capability, alongside a simple one-step co-Attention mechanism to attend to text and image during QA. Our FVQA architecture is faster during inference time, being O(m), as opposed to existing FVQA SOTA methods which are O(N logN), where m is number of vertices, N is number of edges (which is O(m^2)). We observe that our architecture performs comparably in the standard answer-retrieval baseline with existing methods; while for missing-edge reasoning, our KG representation outperforms the SOTA representation by 25%, and image representation outperforms the SOTA representation by 2.6%.