 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecondary Use of Clinical Problem List Entries for Neural Network-Based Disease Code Assignment
Paper and Code
Dec 27, 2021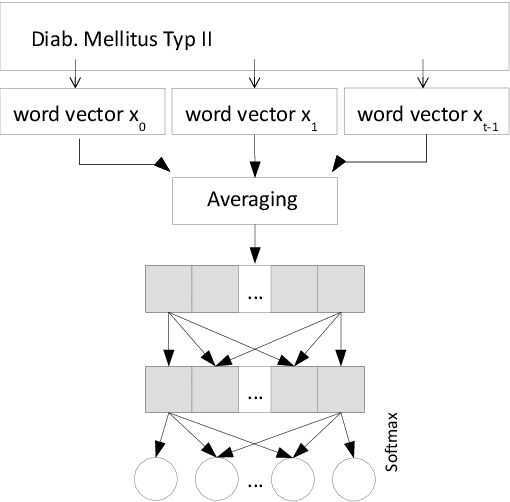
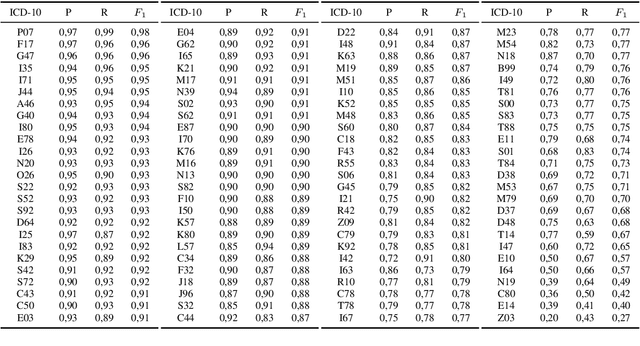
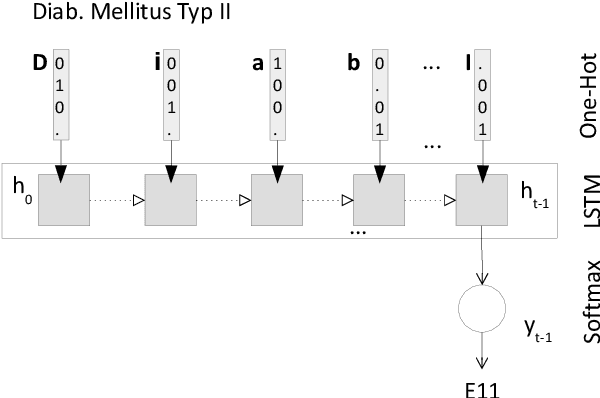
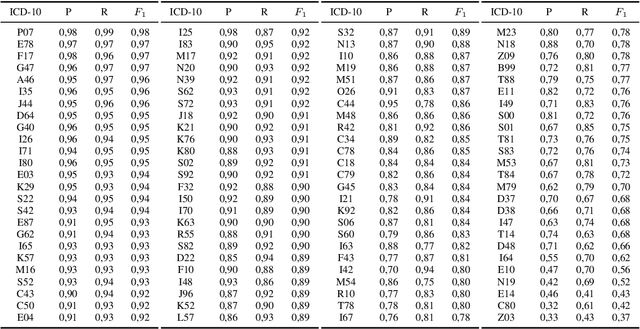
Clinical information systems have become large repositories for semi-structured annotated healthcare data, which have reached a critical mass that makes them interesting for supervised data-driven neural network approaches. We explored automated coding of 50 character long clinical problem list entries using the International Classification of Diseases (ICD-10) and evaluated three different types of network architectures on the top 100 ICD-10 three-digit codes. A fastText baseline reached a macro-averaged F1-measure of 0.83, followed by a character-level LSTM with a macro-averaged F1-measure of 0.84. Top performing was a downstreamed RoBERTa model using a custom language model with a macro-averaged F1-measure of 0.88. A neural network activation analysis together with an investigation of the false positives and false negatives unveiled inconsistent manual coding as a main limiting factor.