Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch Spaces for Neural Model Training
Paper and Code
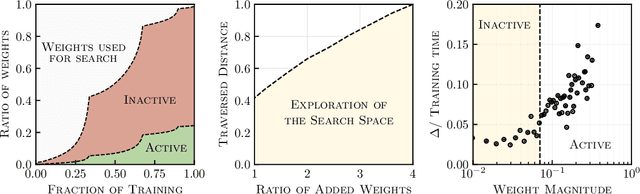
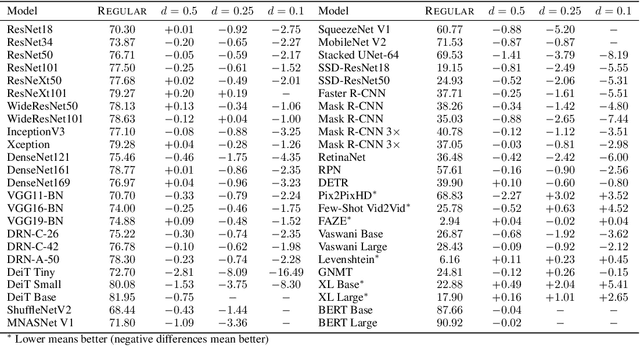
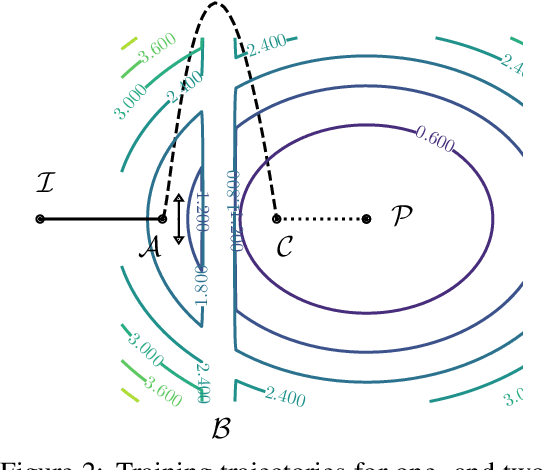
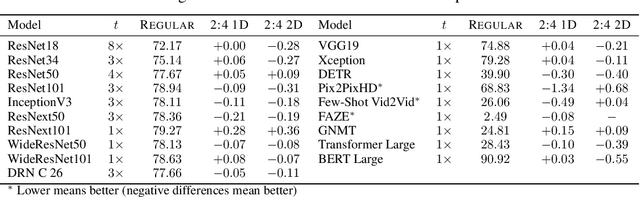
While larger neural models are pushing the boundaries of what deep learning can do, often more weights are needed to train models rather than to run inference for tasks. This paper seeks to understand this behavior using search spaces -- adding weights creates extra degrees of freedom that form new paths for optimization (or wider search spaces) rendering neural model training more effective. We then show how we can augment search spaces to train sparse models attaining competitive scores across dozens of deep learning workloads. They are also are tolerant of structures targeting current hardware, opening avenues for training and inference acceleration. Our work encourages research to explore beyond massive neural models being used today.
View paper on
 OpenReview
OpenReview