 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDAN: Squared Deformable Alignment Network for Learning Misaligned Optical Zoom
Paper and Code
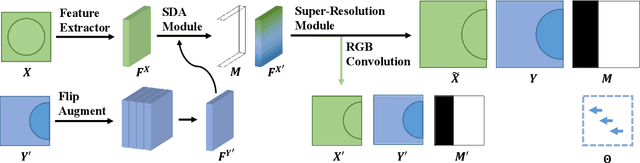
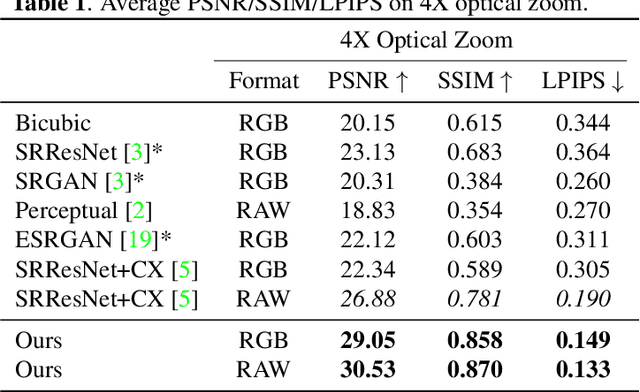
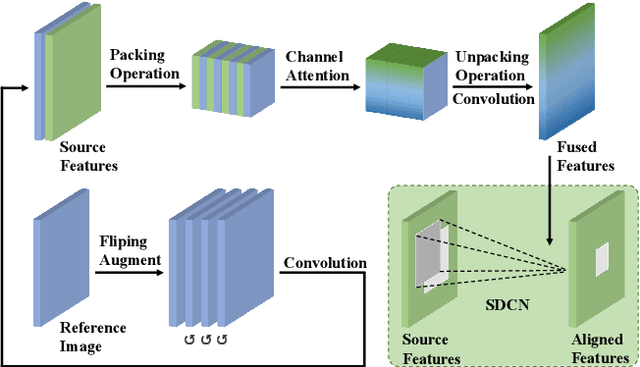

Deep Neural Network (DNN) based super-resolution algorithms have greatly improved the quality of the generated images. However, these algorithms often yield significant artifacts when dealing with real-world super-resolution problems due to the difficulty in learning misaligned optical zoom. In this paper, we introduce a Squared Deformable Alignment Network (SDAN) to address this issue. Our network learns squared per-point offsets for convolutional kernels, and then aligns features in corrected convolutional windows based on the offsets. So the misalignment will be minimized by the extracted aligned features. Different from the per-point offsets used in the vanilla Deformable Convolutional Network (DCN), our proposed squared offsets not only accelerate the offset learning but also improve the generation quality with fewer parameters. Besides, we further propose an efficient cross packing attention layer to boost the accuracy of the learned offsets. It leverages the packing and unpacking operations to enlarge the receptive field of the offset learning and to enhance the ability of extracting the spatial connection between the low-resolution images and the referenced images. Comprehensive experiments show the superiority of our method over other state-of-the-art methods in both computational efficiency and realistic details.