 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScoring Black-Box Models for Adversarial Robustness
Paper and Code
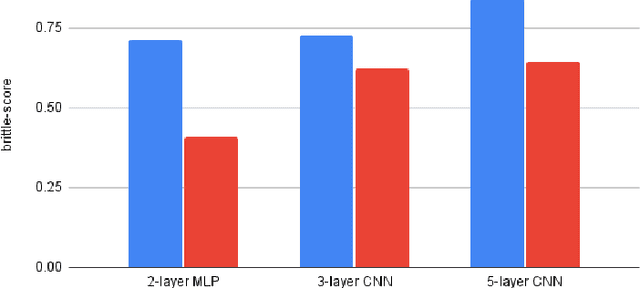
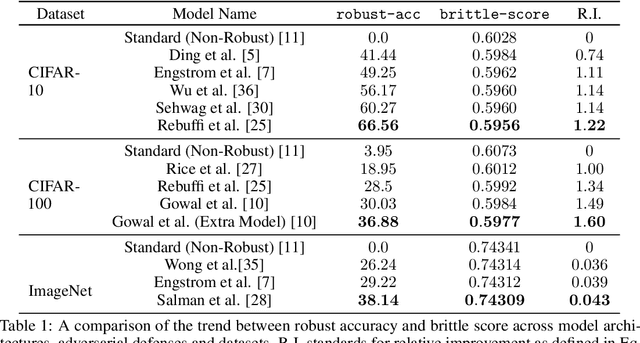
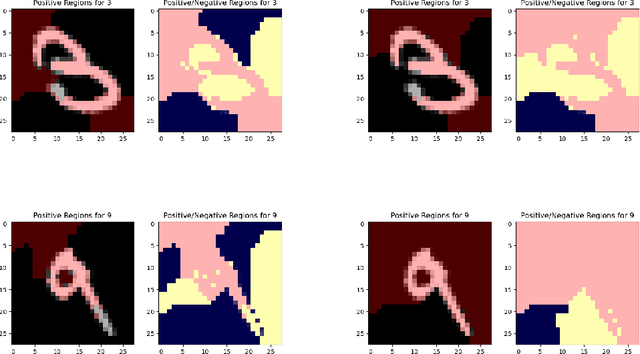
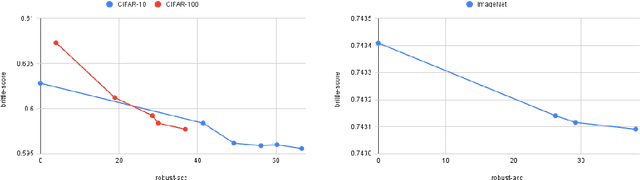
Deep neural networks are susceptible to adversarial inputs and various methods have been proposed to defend these models against adversarial attacks under different perturbation models. The robustness of models to adversarial attacks has been analyzed by first constructing adversarial inputs for the model, and then testing the model performance on the constructed adversarial inputs. Most of these attacks require the model to be white-box, need access to data labels, and finding adversarial inputs can be computationally expensive. We propose a simple scoring method for black-box models which indicates their robustness to adversarial input. We show that adversarially more robust models have a smaller $l_1$-norm of LIME weights and sharper explanations.