Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling up HBM Efficiency of Top-K SpMV for Approximate Embedding Similarity on FPGAs
Paper and Code
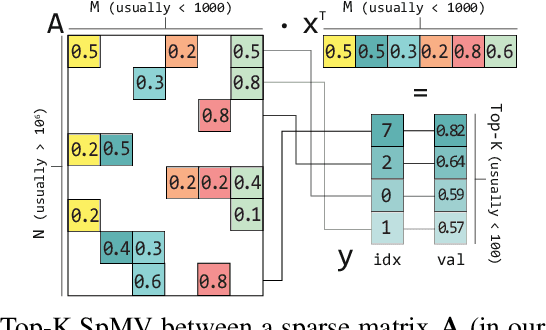
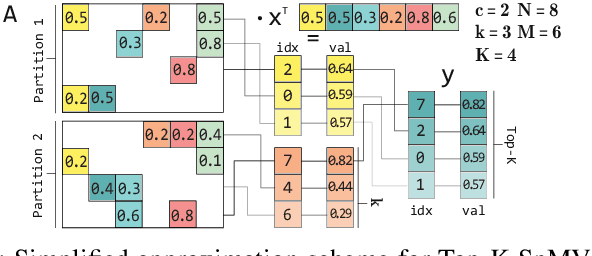
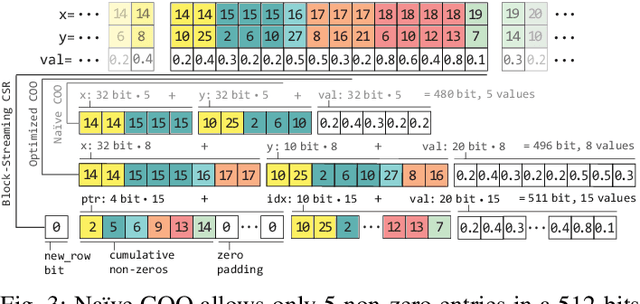
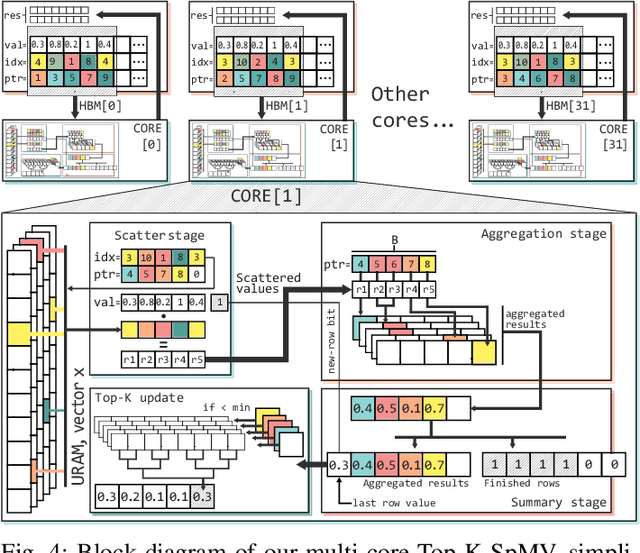
Top-K SpMV is a key component of similarity-search on sparse embeddings. This sparse workload does not perform well on general-purpose NUMA systems that employ traditional caching strategies. Instead, modern FPGA accelerator cards have a few tricks up their sleeve. We introduce a Top-K SpMV FPGA design that leverages reduced precision and a novel packet-wise CSR matrix compression, enabling custom data layouts and delivering bandwidth efficiency often unreachable even in architectures with higher peak bandwidth. With HBM-based boards, we are 100x faster than a multi-threaded CPU implementation and 2x faster than a GPU with 20% higher bandwidth, with 14.2x higher power-efficiency.
* To appear in Proceedings of the 58th Design Automation Conference
(DAC)
View paper on