 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling up Greedy Causal Search for Continuous Variables
Paper and Code
Nov 11, 2015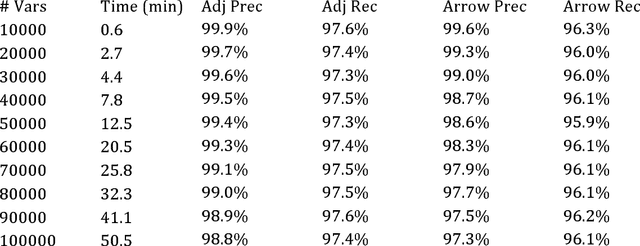

As standardly implemented in R or the Tetrad program, causal search algorithms used most widely or effectively by scientists have severe dimensionality constraints that make them inappropriate for big data problems without sacrificing accuracy. However, implementation improvements are possible. We explore optimizations for the Greedy Equivalence Search that allow search on 50,000-variable problems in 13 minutes for sparse models with 1000 samples on a four-processor, 16G laptop computer. We finish a problem with 1000 samples on 1,000,000 variables in 18 hours for sparse models on a supercomputer node at the Pittsburgh Supercomputing Center with 40 processors and 384 G RAM. The same algorithm can be applied to discrete data, with a slower discrete score, though the discrete implementation currently does not scale as well in our experiments; we have managed to scale up to about 10,000 variables in sparse models with 1000 samples.