 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling up deep neural networks: a capacity allocation perspective
Paper and Code
Mar 27, 2019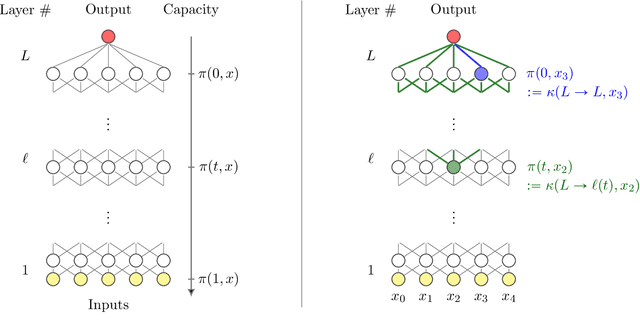
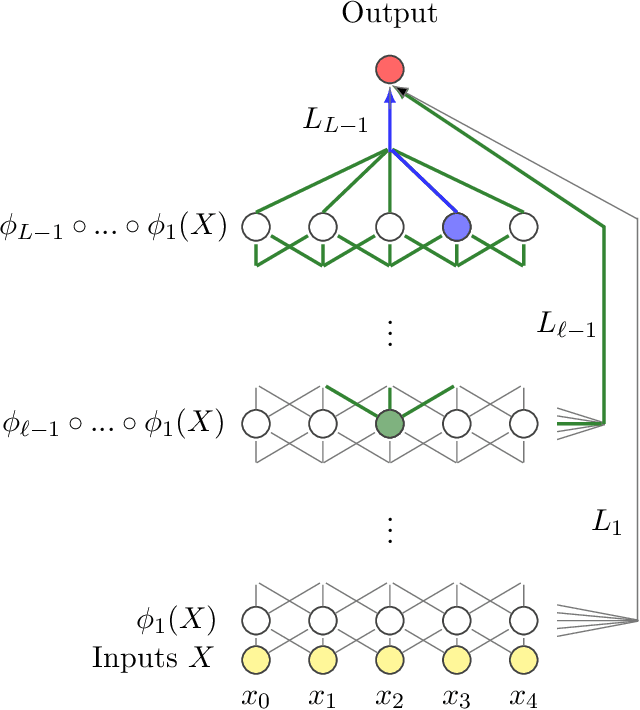
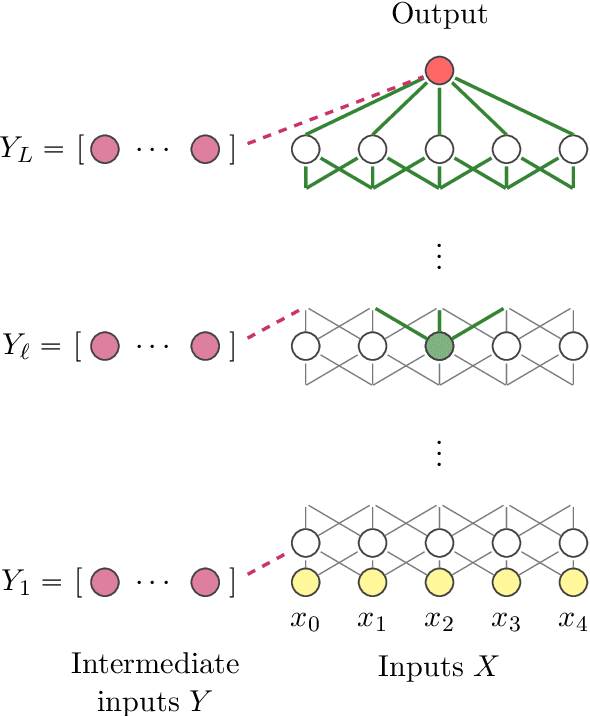
Following the recent work on capacity allocation, we formulate the conjecture that the shattering problem in deep neural networks can only be avoided if the capacity propagation through layers has a non-degenerate continuous limit when the number of layers tends to infinity. This allows us to study a number of commonly used architectures and determine which scaling relations should be enforced in practice as the number of layers grows large. In particular, we recover the conditions of Xavier initialization in the multi-channel case, and we find that weights and biases should be scaled down as the inverse square root of the number of layers for deep residual networks and as the inverse square root of the desired memory length for recurrent networks.