 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for Deep Learning
Paper and Code
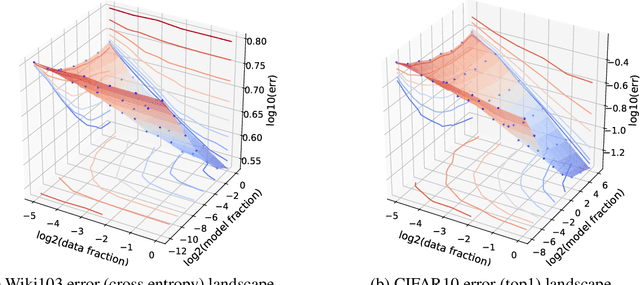
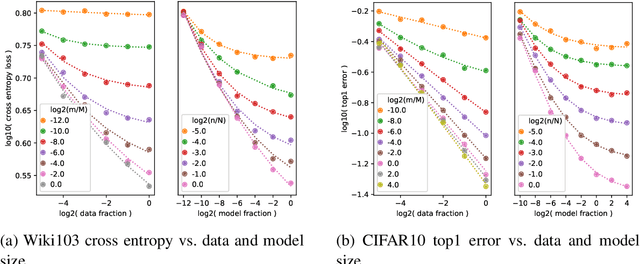
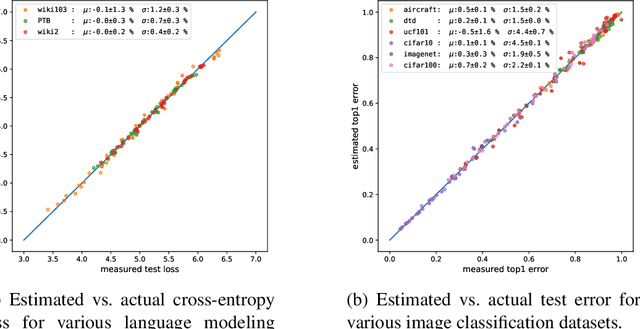
Running faster will only get you so far -- it is generally advisable to first understand where the roads lead, then get a car ... The renaissance of machine learning (ML) and deep learning (DL) over the last decade is accompanied by an unscalable computational cost, limiting its advancement and weighing on the field in practice. In this thesis we take a systematic approach to address the algorithmic and methodological limitations at the root of these costs. We first demonstrate that DL training and pruning are predictable and governed by scaling laws -- for state of the art models and tasks, spanning image classification and language modeling, as well as for state of the art model compression via iterative pruning. Predictability, via the establishment of these scaling laws, provides the path for principled design and trade-off reasoning, currently largely lacking in the field. We then continue to analyze the sources of the scaling laws, offering an approximation-theoretic view and showing through the exploration of a noiseless realizable case that DL is in fact dominated by error sources very far from the lower error limit. We conclude by building on the gained theoretical understanding of the scaling laws' origins. We present a conjectural path to eliminate one of the current dominant error sources -- through a data bandwidth limiting hypothesis and the introduction of Nyquist learners -- which can, in principle, reach the generalization error lower limit (e.g. 0 in the noiseless case), at finite dataset size.