 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Self-Supervised Representation Learning from Spatiotemporal Motion Trajectories for Multimodal Computer Vision
Paper and Code
Oct 07, 2022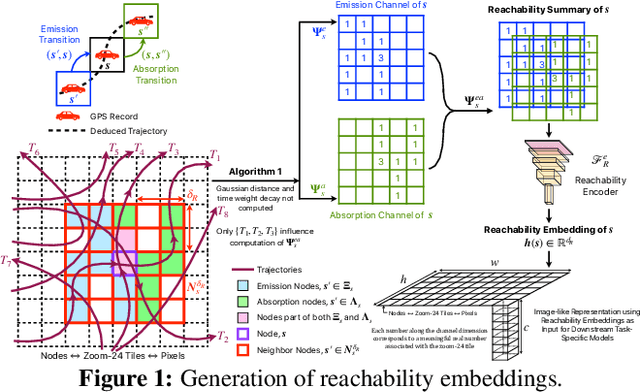

Self-supervised representation learning techniques utilize large datasets without semantic annotations to learn meaningful, universal features that can be conveniently transferred to solve a wide variety of downstream supervised tasks. In this work, we propose a self-supervised method for learning representations of geographic locations from unlabeled GPS trajectories to solve downstream geospatial computer vision tasks. Tiles resulting from a raster representation of the earth's surface are modeled as nodes on a graph or pixels of an image. GPS trajectories are modeled as allowed Markovian paths on these nodes. A scalable and distributed algorithm is presented to compute image-like representations, called reachability summaries, of the spatial connectivity patterns between tiles and their neighbors implied by the observed Markovian paths. A convolutional, contractive autoencoder is trained to learn compressed representations, called reachability embeddings, of reachability summaries for every tile. Reachability embeddings serve as task-agnostic, feature representations of geographic locations. Using reachability embeddings as pixel representations for five different downstream geospatial tasks, cast as supervised semantic segmentation problems, we quantitatively demonstrate that reachability embeddings are semantically meaningful representations and result in 4-23% gain in performance, as measured using area under the precision-recall curve (AUPRC) metric, when compared to baseline models that use pixel representations that do not account for the spatial connectivity between tiles. Reachability embeddings transform sequential, spatiotemporal mobility data into semantically meaningful tensor representations that can be combined with other sources of imagery and are designed to facilitate multimodal learning in geospatial computer vision.