 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Prototype Selection by Genetic Algorithms and Hashing
Paper and Code
Dec 26, 2017
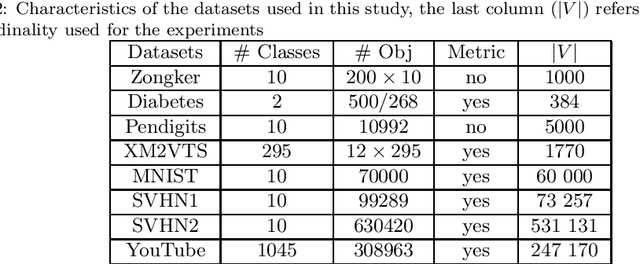
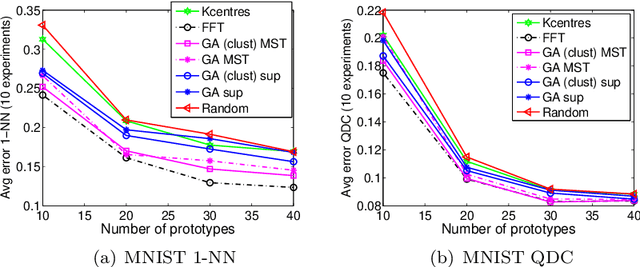
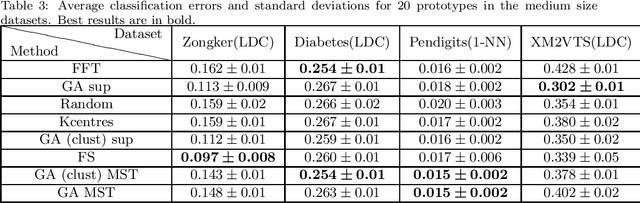
Classification in the dissimilarity space has become a very active research area since it provides a possibility to learn from data given in the form of pairwise non-metric dissimilarities, which otherwise would be difficult to cope with. The selection of prototypes is a key step for the further creation of the space. However, despite previous efforts to find good prototypes, how to select the best representation set remains an open issue. In this paper we proposed scalable methods to select the set of prototypes out of very large datasets. The methods are based on genetic algorithms, dissimilarity-based hashing, and two different unsupervised and supervised scalable criteria. The unsupervised criterion is based on the Minimum Spanning Tree of the graph created by the prototypes as nodes and the dissimilarities as edges. The supervised criterion is based on counting matching labels of objects and their closest prototypes. The suitability of these type of algorithms is analyzed for the specific case of dissimilarity representations. The experimental results showed that the methods select good prototypes taking advantage of the large datasets, and they do so at low runtimes.