 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Projection-Free Optimization
Paper and Code
May 07, 2021
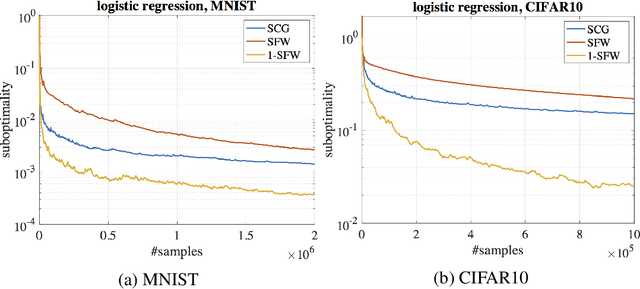


As a projection-free algorithm, Frank-Wolfe (FW) method, also known as conditional gradient, has recently received considerable attention in the machine learning community. In this dissertation, we study several topics on the FW variants for scalable projection-free optimization. We first propose 1-SFW, the first projection-free method that requires only one sample per iteration to update the optimization variable and yet achieves the best known complexity bounds for convex, non-convex, and monotone DR-submodular settings. Then we move forward to the distributed setting, and develop Quantized Frank-Wolfe (QFW), a general communication-efficient distributed FW framework for both convex and non-convex objective functions. We study the performance of QFW in two widely recognized settings: 1) stochastic optimization and 2) finite-sum optimization. Finally, we propose Black-Box Continuous Greedy, a derivative-free and projection-free algorithm, that maximizes a monotone continuous DR-submodular function over a bounded convex body in Euclidean space.