 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Distributed Approximation of Internal Measures for Clustering Evaluation
Paper and Code
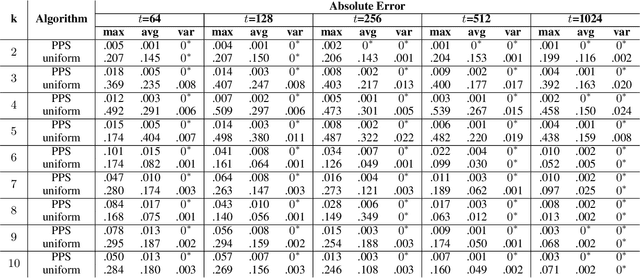
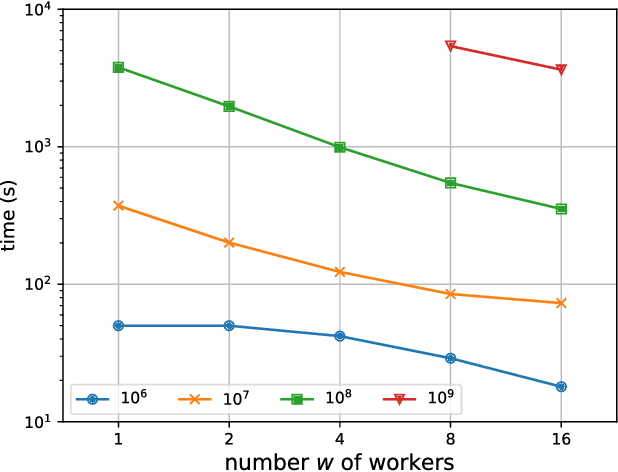
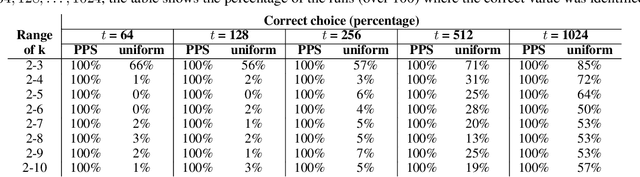
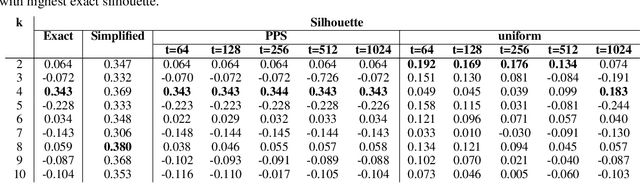
The most widely used internal measure for clustering evaluation is the silhouette coefficient, whose naive computation requires a quadratic number of distance calculations, which is clearly unfeasible for massive datasets. Surprisingly, there are no known general methods to efficiently approximate the silhouette coefficient of a clustering with rigorously provable high accuracy. In this paper, we present the first scalable algorithm to compute such a rigorous approximation for the evaluation of clusterings based on any metric distances. Our algorithm hinges on a Probability Proportional to Size (PPS) sampling scheme, and, for any fixed $\varepsilon, \delta \in (0,1)$, it approximates the silhouette coefficient within a mere additive error $O(\varepsilon)$ with probability $1-\delta$, using a very small number of distance calculations. We also prove that the algorithm can be adapted to obtain rigorous approximations of other internal measures of clustering quality, such as cohesion and separation. Importantly, we provide a distributed implementation of the algorithm using the MapReduce model, which runs in constant rounds and requires only sublinear local space at each worker, which makes our estimation approach applicable to big data scenarios. We perform an extensive experimental evaluation of our silhouette approximation algorithm, comparing its performance to a number of baseline heuristics on real and synthetic datasets. The experiments provide evidence that, unlike other heuristics, our estimation strategy not only provides tight theoretical guarantees but is also able to return highly accurate estimations while running in a fraction of the time required by the exact computation, and that its distributed implementation is highly scalable, thus enabling the computation of internal measures for very large datasets for which the exact computation is prohibitive.