 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Cross-lingual Document Similarity through Language-specific Concept Hierarchies
Paper and Code
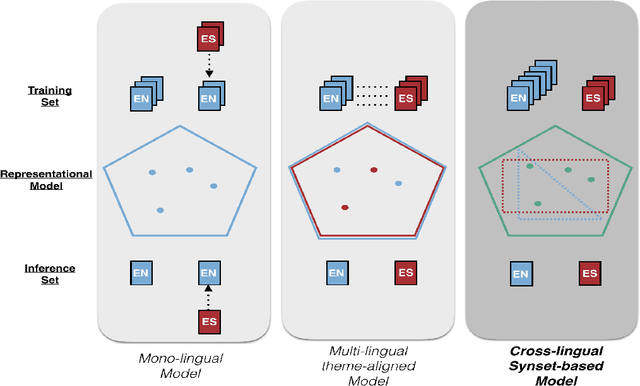
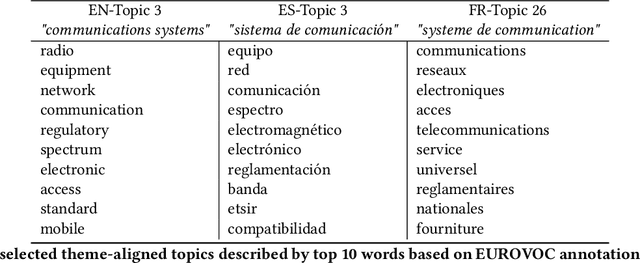
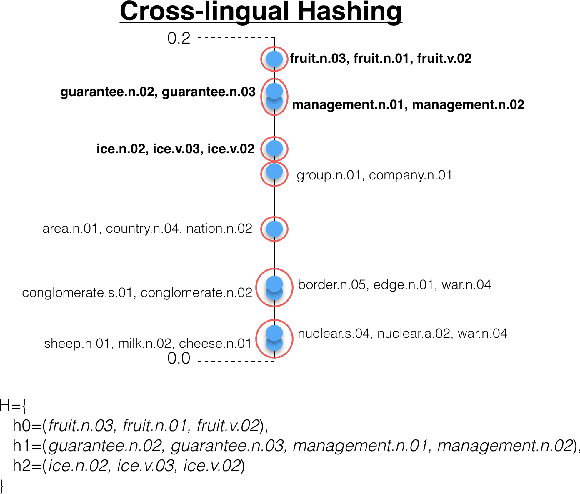
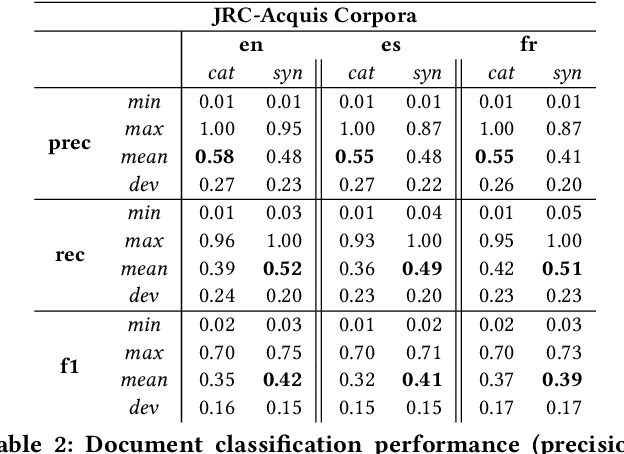
With the ongoing growth in number of digital articles in a wider set of languages and the expanding use of different languages, we need annotation methods that enable browsing multi-lingual corpora. Multilingual probabilistic topic models have recently emerged as a group of semi-supervised machine learning models that can be used to perform thematic explorations on collections of texts in multiple languages. However, these approaches require theme-aligned training data to create a language-independent space. This constraint limits the amount of scenarios that this technique can offer solutions to train and makes it difficult to scale up to situations where a huge collection of multi-lingual documents are required during the training phase. This paper presents an unsupervised document similarity algorithm that does not require parallel or comparable corpora, or any other type of translation resource. The algorithm annotates topics automatically created from documents in a single language with cross-lingual labels and describes documents by hierarchies of multi-lingual concepts from independently-trained models. Experiments performed on the English, Spanish and French editions of JCR-Acquis corpora reveal promising results on classifying and sorting documents by similar content.