 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Bottom-up Subspace Clustering using FP-Trees for High Dimensional Data
Paper and Code
Nov 07, 2018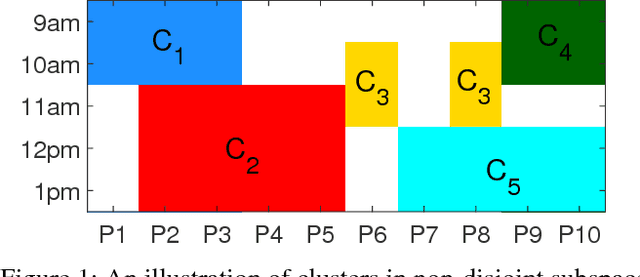
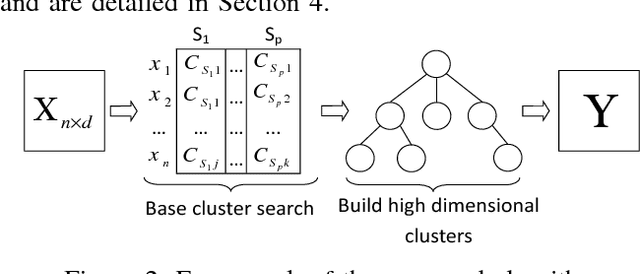
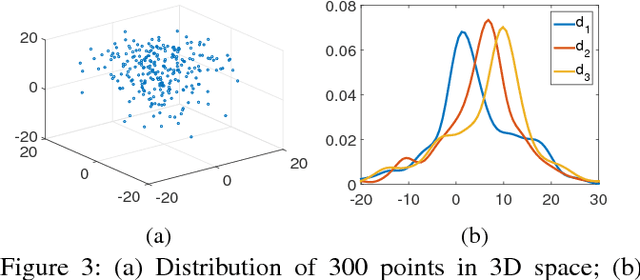
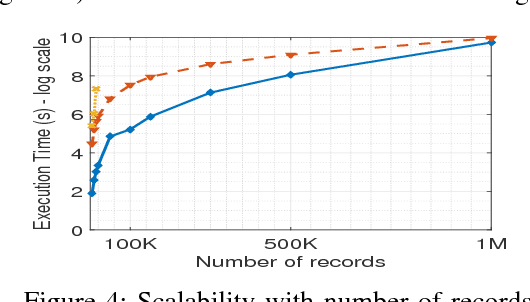
Subspace clustering aims to find groups of similar objects (clusters) that exist in lower dimensional subspaces from a high dimensional dataset. It has a wide range of applications, such as analysing high dimensional sensor data or DNA sequences. However, existing algorithms have limitations in finding clusters in non-disjoint subspaces and scaling to large data, which impinge their applicability in areas such as bioinformatics and the Internet of Things. We aim to address such limitations by proposing a subspace clustering algorithm using a bottom-up strategy. Our algorithm first searches for base clusters in low dimensional subspaces. It then forms clusters in higher-dimensional subspaces using these base clusters, which we formulate as a frequent pattern mining problem. This formulation enables efficient search for clusters in higher-dimensional subspaces, which is done using FP-trees. The proposed algorithm is evaluated against traditional bottom-up clustering algorithms and state-of-the-art subspace clustering algorithms. The experimental results show that the proposed algorithm produces clusters with high accuracy, and scales well to large volumes of data. We also demonstrate the algorithm's performance using real-life data, including ten genomic datasets and a car parking occupancy dataset.