 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Bayesian Optimization Using Vecchia Approximations of Gaussian Processes
Paper and Code
Mar 02, 2022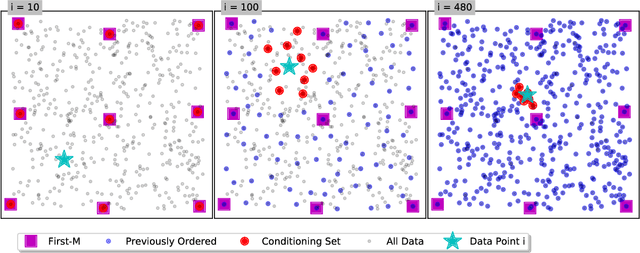
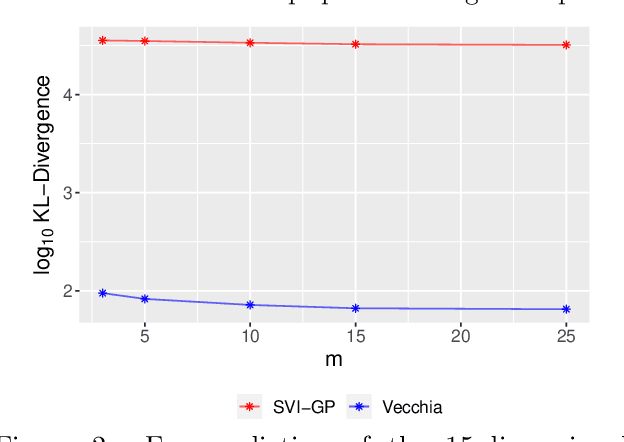
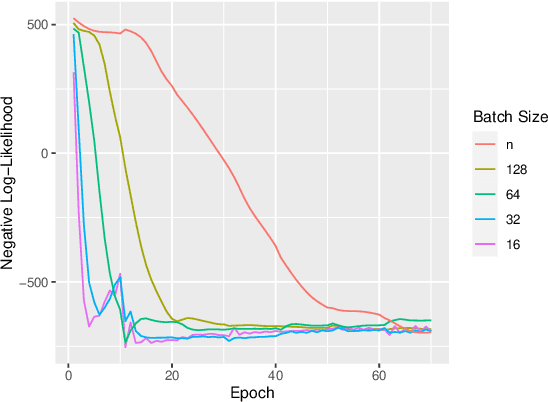
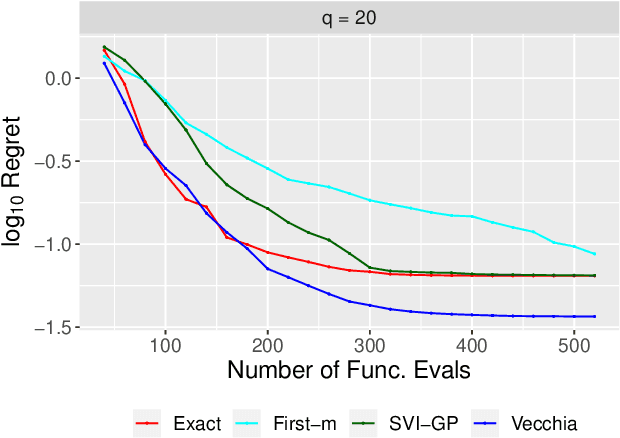
Bayesian optimization is a technique for optimizing black-box target functions. At the core of Bayesian optimization is a surrogate model that predicts the output of the target function at previously unseen inputs to facilitate the selection of promising input values. Gaussian processes (GPs) are commonly used as surrogate models but are known to scale poorly with the number of observations. We adapt the Vecchia approximation, a popular GP approximation from spatial statistics, to enable scalable high-dimensional Bayesian optimization. We develop several improvements and extensions, including training warped GPs using mini-batch gradient descent, approximate neighbor search, and selecting multiple input values in parallel. We focus on the use of our warped Vecchia GP in trust-region Bayesian optimization via Thompson sampling. On several test functions and on two reinforcement-learning problems, our methods compared favorably to the state of the art.