 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaLA: Accelerating Adaptation of Pre-Trained Transformer-Based Language Models via Efficient Large-Batch Adversarial Noise
Paper and Code
Jan 29, 2022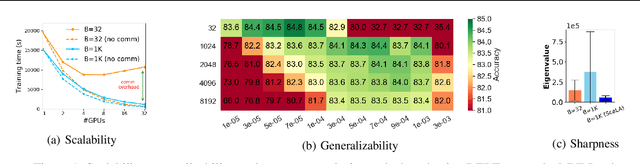
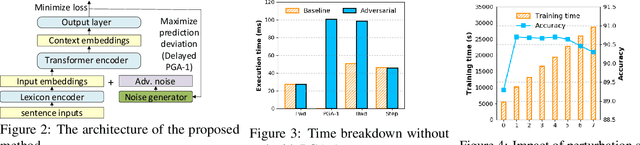


In recent years, large pre-trained Transformer-based language models have led to dramatic improvements in many natural language understanding tasks. To train these models with increasing sizes, many neural network practitioners attempt to increase the batch sizes in order to leverage multiple GPUs to improve training speed. However, increasing the batch size often makes the optimization more difficult, leading to slow convergence or poor generalization that can require orders of magnitude more training time to achieve the same model quality. In this paper, we explore the steepness of the loss landscape of large-batch optimization for adapting pre-trained Transformer-based language models to domain-specific tasks and find that it tends to be highly complex and irregular, posing challenges to generalization on downstream tasks. To tackle this challenge, we propose ScaLA, a novel and efficient method to accelerate the adaptation speed of pre-trained transformer networks. Different from prior methods, we take a sequential game-theoretic approach by adding lightweight adversarial noise into large-batch optimization, which significantly improves adaptation speed while preserving model generalization. Experiment results show that ScaLA attains 2.7--9.8$\times$ adaptation speedups over the baseline for GLUE on BERT-base and RoBERTa-large, while achieving comparable and sometimes higher accuracy than the state-of-the-art large-batch optimization methods. Finally, we also address the theoretical aspect of large-batch optimization with adversarial noise and provide a theoretical convergence rate analysis for ScaLA using techniques for analyzing non-convex saddle-point problems.