 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Efficient Training in Multi-Agent Adversarial Games with Limited Teammate Communication
Paper and Code
Nov 01, 2020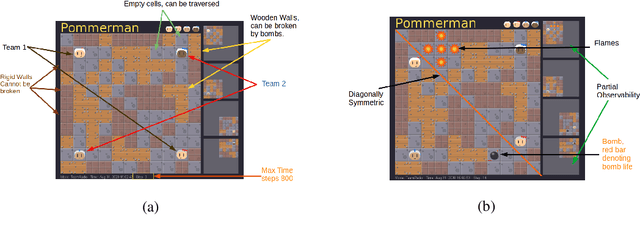
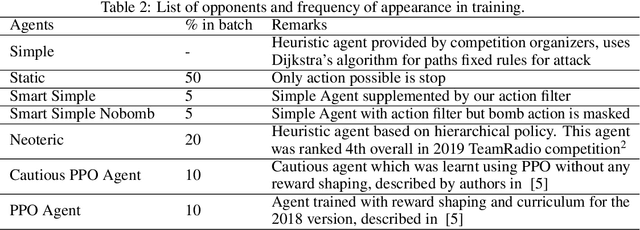
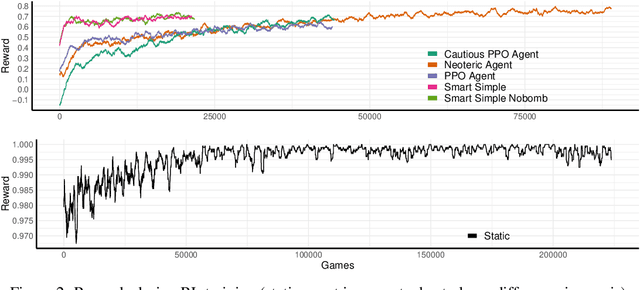

We describe our solution approach for Pommerman TeamRadio, a competition environment associated with NeurIPS 2019. The defining feature of our algorithm is achieving sample efficiency within a restrictive computational budget while beating the previous years learning agents. The proposed algorithm (i) uses imitation learning to seed the policy, (ii) explicitly defines the communication protocol between the two teammates, (iii) shapes the reward to provide a richer feedback signal to each agent during training and (iv) uses masking for catastrophic bad actions. We describe extensive tests against baselines, including those from the 2019 competition leaderboard, and also a specific investigation of the learned policy and the effect of each modification on performance. We show that the proposed approach is able to achieve competitive performance within half a million games of training, significantly faster than other studies in the literature.