 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Efficient Reinforcement Learning through Transfer and Architectural Priors
Paper and Code
Jan 07, 2018

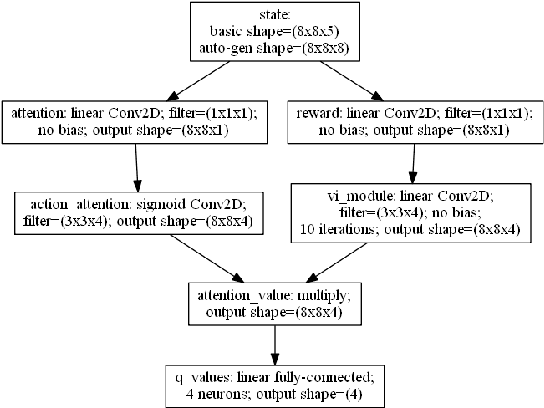
Recent work in deep reinforcement learning has allowed algorithms to learn complex tasks such as Atari 2600 games just from the reward provided by the game, but these algorithms presently require millions of training steps in order to learn, making them approximately five orders of magnitude slower than humans. One reason for this is that humans build robust shared representations that are applicable to collections of problems, making it much easier to assimilate new variants. This paper first introduces the idea of automatically-generated game sets to aid in transfer learning research, and then demonstrates the utility of shared representations by showing that models can substantially benefit from the incorporation of relevant architectural priors. This technique affords a remarkable 50x positive transfer on a toy problem-set.