 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM-I2I: Unleash the Power of Segment Anything Model for Medical Image Translation
Paper and Code
Nov 13, 2024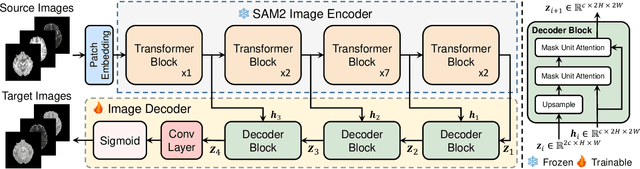


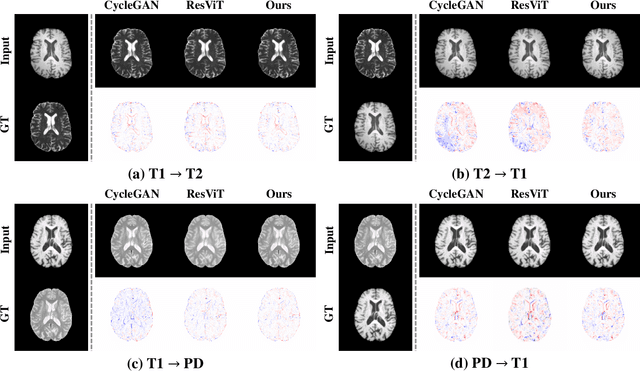
Medical image translation is crucial for reducing the need for redundant and expensive multi-modal imaging in clinical field. However, current approaches based on Convolutional Neural Networks (CNNs) and Transformers often fail to capture fine-grain semantic features, resulting in suboptimal image quality. To address this challenge, we propose SAM-I2I, a novel image-to-image translation framework based on the Segment Anything Model 2 (SAM2). SAM-I2I utilizes a pre-trained image encoder to extract multiscale semantic features from the source image and a decoder, based on the mask unit attention module, to synthesize target modality images. Our experiments on multi-contrast MRI datasets demonstrate that SAM-I2I outperforms state-of-the-art methods, offering more efficient and accurate medical image translation.