 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaLite : A light-weight model for salient object detection
Paper and Code

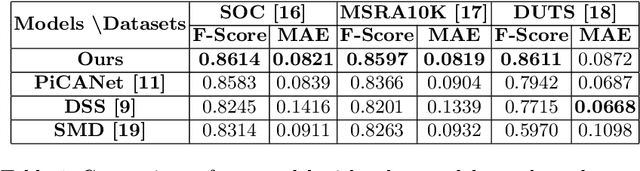
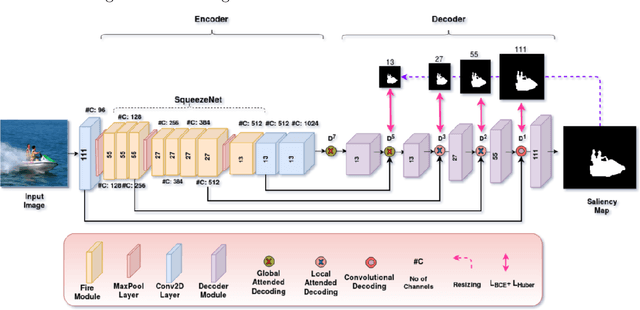
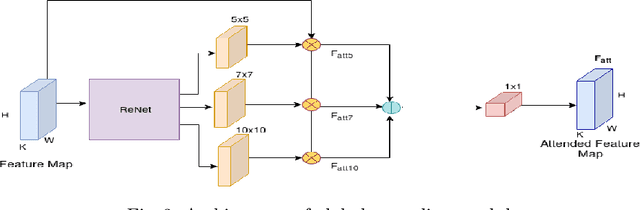
Salient object detection is a prevalent computer vision task that has applications ranging from abnormality detection to abnormality processing. Context modelling is an important criterion in the domain of saliency detection. A global context helps in determining the salient object in a given image by contrasting away other objects in the global view of the scene. However, the local context features detects the boundaries of the salient object with higher accuracy in a given region. To incorporate the best of both worlds, our proposed SaLite model uses both global and local contextual features. It is an encoder-decoder based architecture in which the encoder uses a lightweight SqueezeNet and decoder is modelled using convolution layers. Modern deep based models entitled for saliency detection use a large number of parameters, which is difficult to deploy on embedded systems. This paper attempts to solve the above problem using SaLite which is a lighter process for salient object detection without compromising on performance. Our approach is extensively evaluated on three publicly available datasets namely DUTS, MSRA10K, and SOC. Experimental results show that our proposed SaLite has significant and consistent improvements over the state-of-the-art methods.