 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency-guided video classification via adaptively weighted learning
Paper and Code
Mar 26, 2017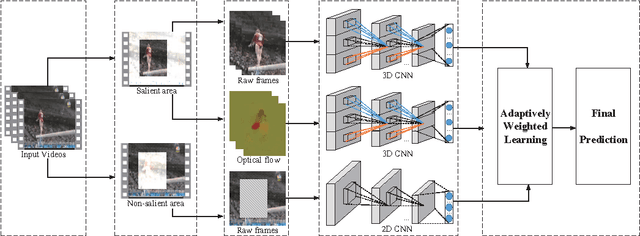

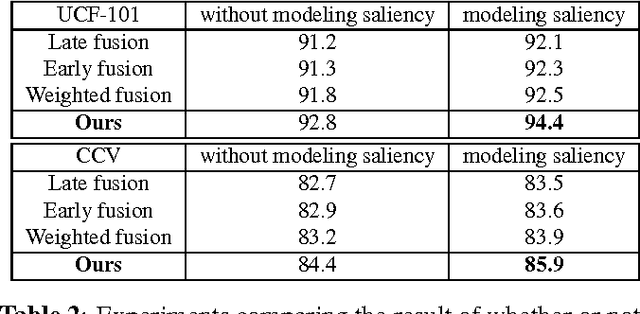

Video classification is productive in many practical applications, and the recent deep learning has greatly improved its accuracy. However, existing works often model video frames indiscriminately, but from the view of motion, video frames can be decomposed into salient and non-salient areas naturally. Salient and non-salient areas should be modeled with different networks, for the former present both appearance and motion information, and the latter present static background information. To address this problem, in this paper, video saliency is predicted by optical flow without supervision firstly. Then two streams of 3D CNN are trained individually for raw frames and optical flow on salient areas, and another 2D CNN is trained for raw frames on non-salient areas. For the reason that these three streams play different roles for each class, the weights of each stream are adaptively learned for each class. Experimental results show that saliency-guided modeling and adaptively weighted learning can reinforce each other, and we achieve the state-of-the-art results.