 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRyanSpeech: A Corpus for Conversational Text-to-Speech Synthesis
Paper and Code
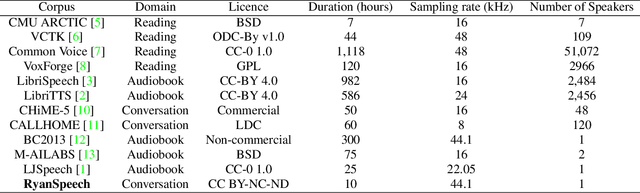
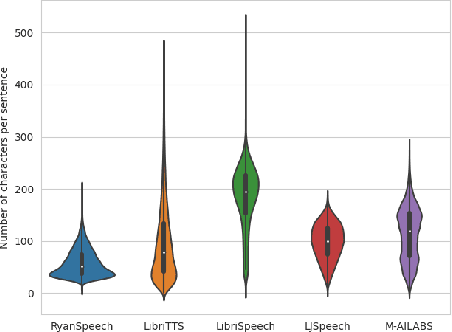
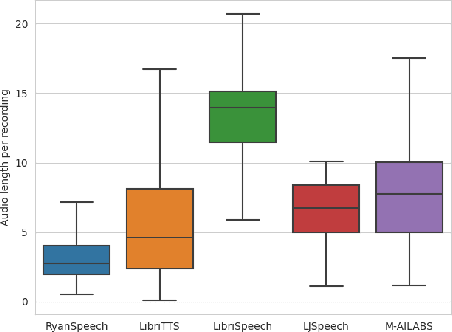
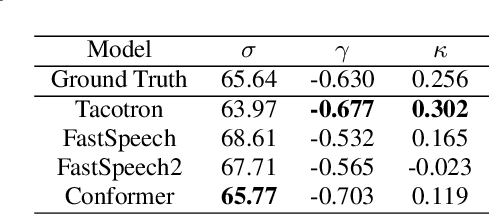
This paper introduces RyanSpeech, a new speech corpus for research on automated text-to-speech (TTS) systems. Publicly available TTS corpora are often noisy, recorded with multiple speakers, or lack quality male speech data. In order to meet the need for a high quality, publicly available male speech corpus within the field of speech recognition, we have designed and created RyanSpeech which contains textual materials from real-world conversational settings. These materials contain over 10 hours of a professional male voice actor's speech recorded at 44.1 kHz. This corpus's design and pipeline make RyanSpeech ideal for developing TTS systems in real-world applications. To provide a baseline for future research, protocols, and benchmarks, we trained 4 state-of-the-art speech models and a vocoder on RyanSpeech. The results show 3.36 in mean opinion scores (MOS) in our best model. We have made both the corpus and trained models for public use.