 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuminating Word Representations with Random Noised Masker
Paper and Code
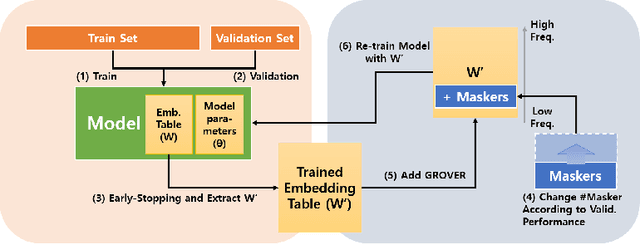
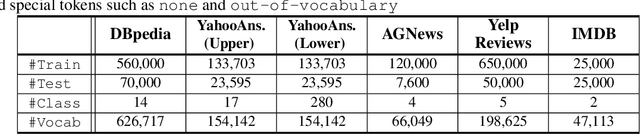
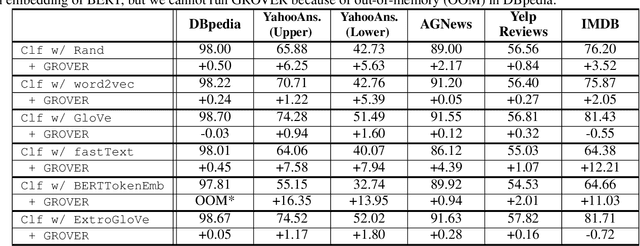
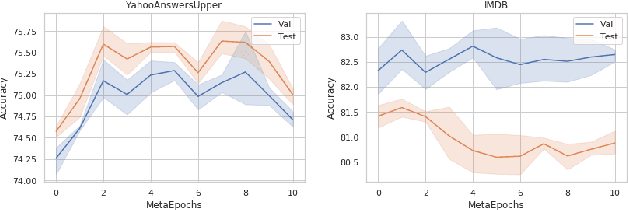
We introduce a training method for both better word representation and performance, which we call GROVER (Gradual Rumination On the Vector with maskERs). The method is to gradually and iteratively add random noises to word embeddings while training a model. GROVER first starts from conventional training process, and then extracts the fine-tuned representations. Next, we gradually add random noises to the word representations and repeat the training process from scratch, but initialize with the noised word representations. Through the re-training process, we can mitigate some noises to be compensated and utilize other noises to learn better representations. As a result, we can get word representations further fine-tuned and specialized on the task. When we experiment with our method on 5 text classification datasets, our method improves model performances on most of the datasets. Moreover, we show that our method can be combined with other regularization techniques, further improving the model performance.