Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuBioRoBERTa: a pre-trained biomedical language model for Russian language biomedical text mining
Paper and Code
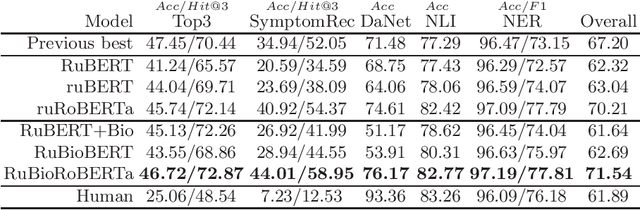

This paper presents several BERT-based models for Russian language biomedical text mining (RuBioBERT, RuBioRoBERTa). The models are pre-trained on a corpus of freely available texts in the Russian biomedical domain. With this pre-training, our models demonstrate state-of-the-art results on RuMedBench - Russian medical language understanding benchmark that covers a diverse set of tasks, including text classification, question answering, natural language inference, and named entity recognition.
View paper on