 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPNet: an End-to-End Network for Relative Camera Pose Estimation
Paper and Code
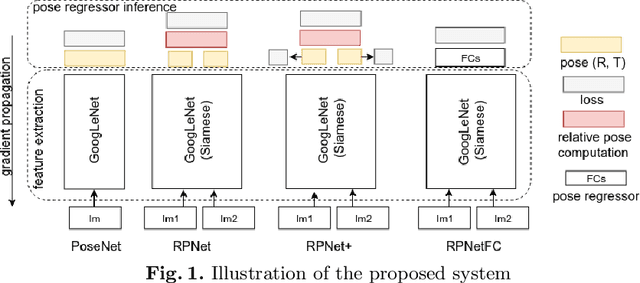


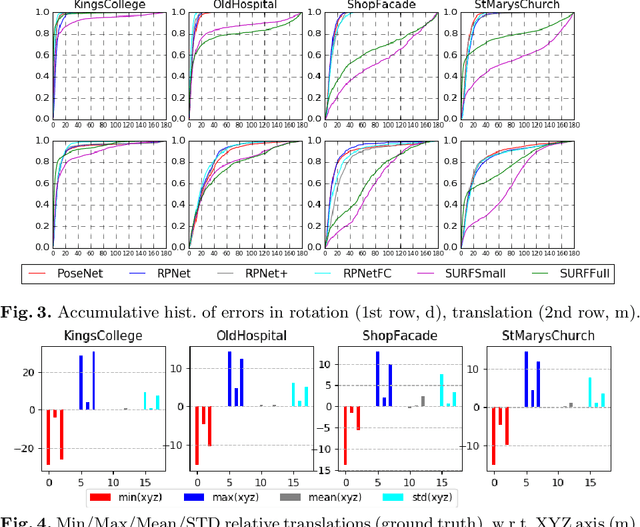
This paper addresses the task of relative camera pose estimation from raw image pixels, by means of deep neural networks. The proposed RPNet network takes pairs of images as input and directly infers the relative poses, without the need of camera intrinsic/extrinsic. While state-of-the-art systems based on SIFT + RANSAC, are able to recover the translation vector only up to scale, RPNet is trained to produce the full translation vector, in an end-to-end way. Experimental results on the Cambridge Landmark dataset show very promising results regarding the recovery of the full translation vector. They also show that RPNet produces more accurate and more stable results than traditional approaches, especially for hard images (repetitive textures, textureless images, etc). To the best of our knowledge, RPNet is the first attempt to recover full translation vectors in relative pose estimation.