 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRow-wise Accelerator for Vision Transformer
Paper and Code
May 09, 2022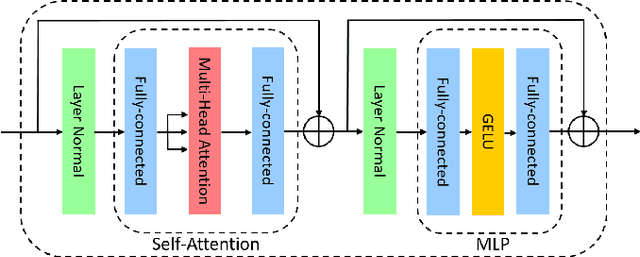

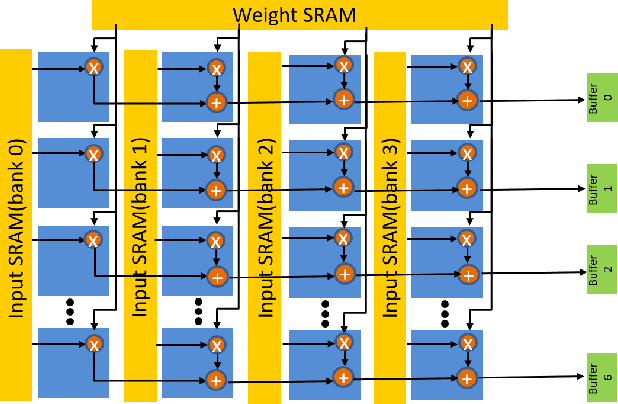

Following the success of the natural language processing, the transformer for vision applications has attracted significant attention in recent years due to its excellent performance. However, existing deep learning hardware accelerators for vision cannot execute this structure efficiently due to significant model architecture differences. As a result, this paper proposes the hardware accelerator for vision transformers with row-wise scheduling, which decomposes major operations in vision transformers as a single dot product primitive for a unified and efficient execution. Furthermore, by sharing weights in columns, we can reuse the data and reduce the usage of memory. The implementation with TSMC 40nm CMOS technology only requires 262K gate count and 149KB SRAM buffer for 403.2 GOPS throughput at 600MHz clock frequency.