 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROS Regression: Integrating Regularization and Optimal Scaling Regression
Paper and Code
Nov 16, 2016
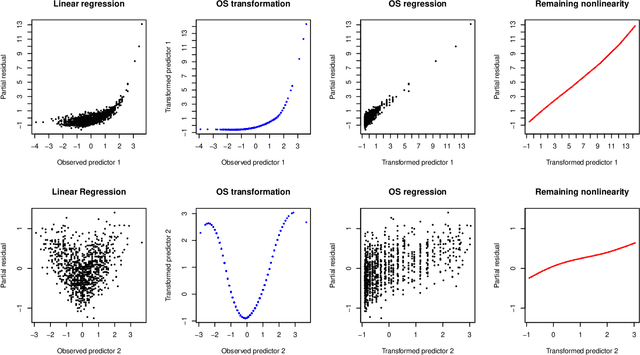
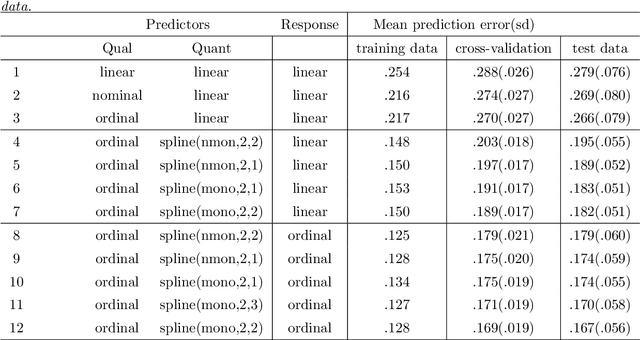
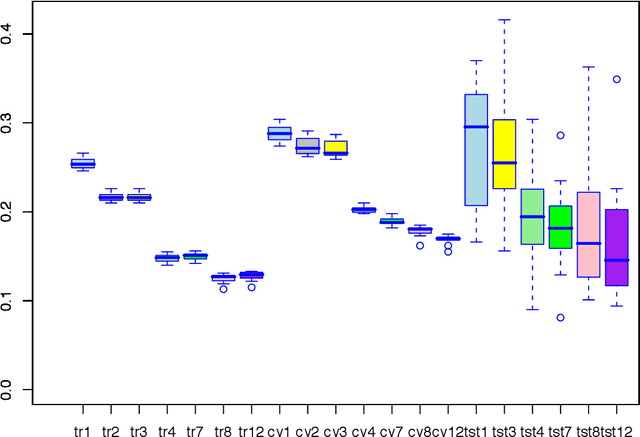
In this paper we combine two important extensions of ordinary least squares regression: regularization and optimal scaling. Optimal scaling (sometimes also called optimal scoring) has originally been developed for categorical data, and the process finds quantifications for the categories that are optimal for the regression model in the sense that they maximize the multiple correlation. Although the optimal scaling method was developed initially for variables with a limited number of categories, optimal transformations of continuous variables are a special case. We will consider a variety of transformation types; typically we use step functions for categorical variables, and smooth (spline) functions for continuous variables. Both types of functions can be restricted to be monotonic, preserving the ordinal information in the data. In addition to optimal scaling, three regularization methods will be considered: Ridge regression, the Lasso, and the Elastic Net. The resulting method will be called ROS Regression (Regularized Optimal Scaling Regression. We will show that the basic OS algorithm provides straightforward and efficient estimation of the regularized regression coefficients, automatically gives the Group Lasso and Blockwise Sparse Regression, and extends them with monotonicity properties. We will show that Optimal Scaling linearizes nonlinear relationships between predictors and outcome, and improves upon the condition of the predictor correlation matrix, increasing (on average) the conditional independence of the predictors. Alternative options for regularization of either regression coefficients or category quantifications are mentioned. Extended examples are provided. Keywords: Categorical Data, Optimal Scaling, Conditional Independence, Step Functions, Splines, Monotonic Transformations, Regularization, Lasso, Elastic Net, Group Lasso, Blockwise Sparse Regression.