 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness of Visual Explanations to Common Data Augmentation
Paper and Code
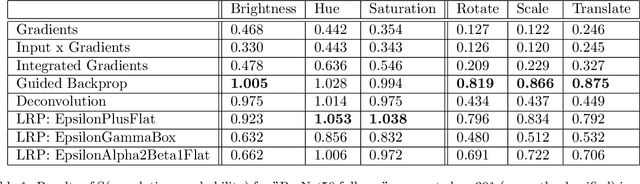
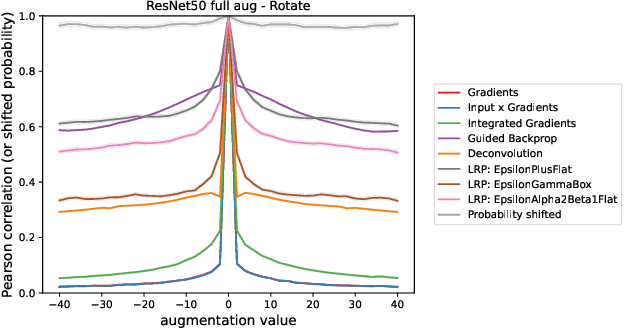
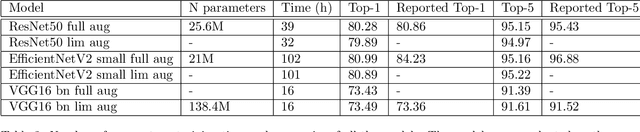
As the use of deep neural networks continues to grow, understanding their behaviour has become more crucial than ever. Post-hoc explainability methods are a potential solution, but their reliability is being called into question. Our research investigates the response of post-hoc visual explanations to naturally occurring transformations, often referred to as augmentations. We anticipate explanations to be invariant under certain transformations, such as changes to the colour map while responding in an equivariant manner to transformations like translation, object scaling, and rotation. We have found remarkable differences in robustness depending on the type of transformation, with some explainability methods (such as LRP composites and Guided Backprop) being more stable than others. We also explore the role of training with data augmentation. We provide evidence that explanations are typically less robust to augmentation than classification performance, regardless of whether data augmentation is used in training or not.