 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Super-Resolution GAN, with Manifold-based and Perception Loss
Paper and Code
Mar 16, 2019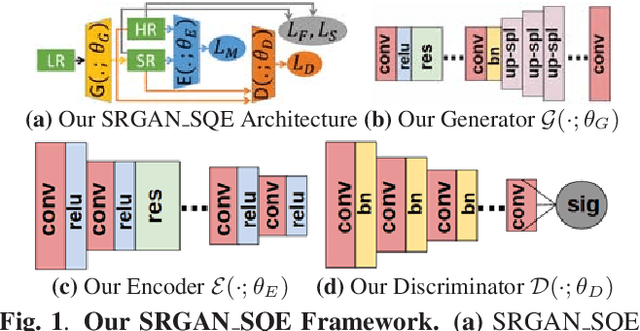
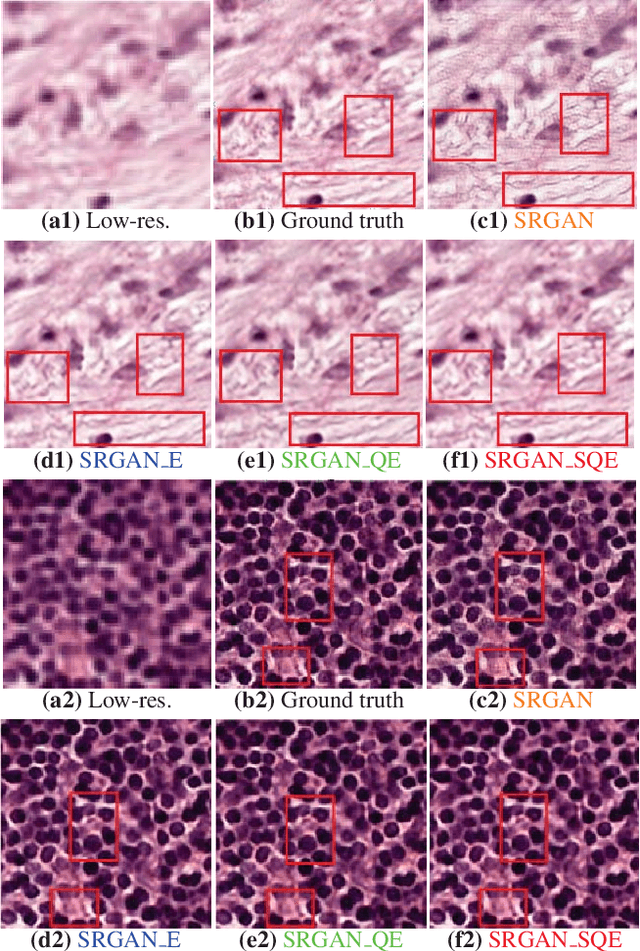
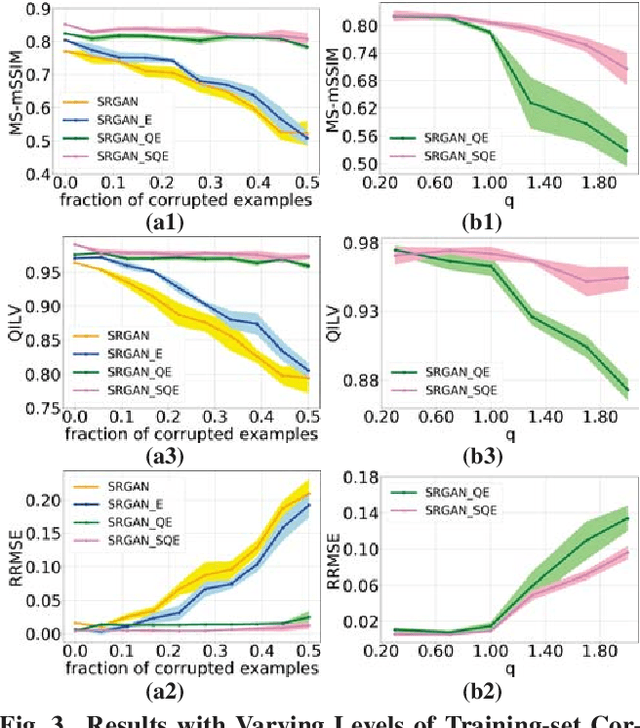
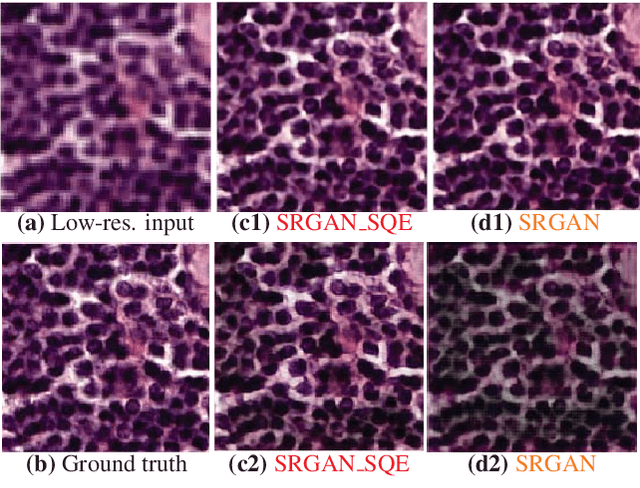
Super-resolution using deep neural networks typically relies on highly curated training sets that are often unavailable in clinical deployment scenarios. Using loss functions that assume Gaussian-distributed residuals makes the learning sensitive to corruptions in clinical training sets. We propose novel loss functions that are robust to corruptions in training sets by modeling heavy-tailed non-Gaussian distributions on the residuals. We propose a loss based on an autoencoder-based manifold-distance between the super-resolved and high-resolution images, to reproduce realistic textural content in super-resolved images. We propose to learn to super-resolve images to match human perceptions of structure, luminance, and contrast. Results on a large clinical dataset shows the advantages of each of our contributions, where our framework improves over the state of the art.