 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust High-Resolution Video Matting with Temporal Guidance
Paper and Code
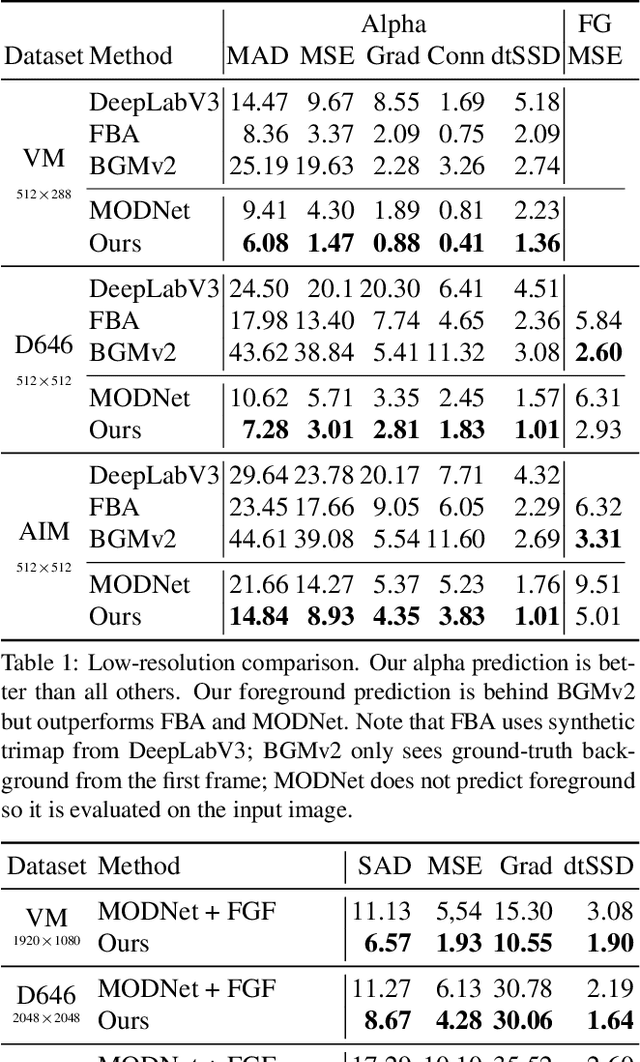
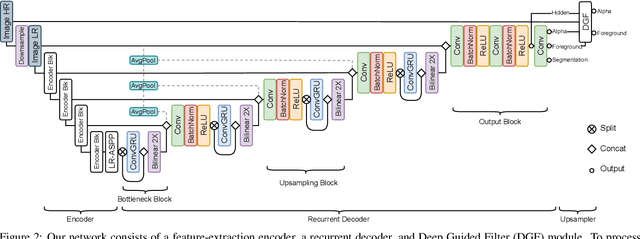

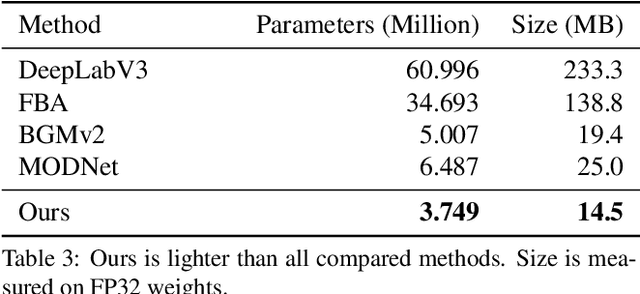
We introduce a robust, real-time, high-resolution human video matting method that achieves new state-of-the-art performance. Our method is much lighter than previous approaches and can process 4K at 76 FPS and HD at 104 FPS on an Nvidia GTX 1080Ti GPU. Unlike most existing methods that perform video matting frame-by-frame as independent images, our method uses a recurrent architecture to exploit temporal information in videos and achieves significant improvements in temporal coherence and matting quality. Furthermore, we propose a novel training strategy that enforces our network on both matting and segmentation objectives. This significantly improves our model's robustness. Our method does not require any auxiliary inputs such as a trimap or a pre-captured background image, so it can be widely applied to existing human matting applications.