 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust GANs against Dishonest Adversaries
Paper and Code

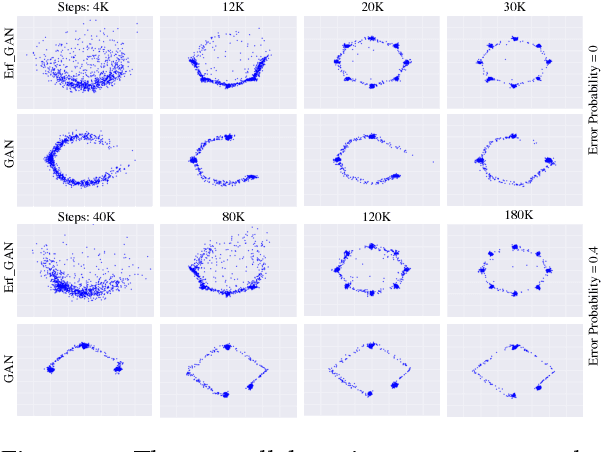

Robustness of deep learning models is a property that has recently gained increasing attention. We formally define a notion of robustness for generative adversarial models, and show that, perhaps surprisingly, the GAN in its original form is not robust. Indeed, the discriminator in GANs may be viewed as merely offering "teaching feedback". Our notion of robustness relies on a dishonest discriminator, or noisy, adversarial interference with its feedback. We explore, theoretically and empirically, the effect of model and training properties on this robustness. In particular, we show theoretical conditions for robustness that are supported by empirical evidence. We also test the effect of regularization. Our results suggest variations of GANs that are indeed more robust to noisy attacks, and have overall more stable training behavior.