 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust empirical risk minimization via Newton's method
Paper and Code
Jan 30, 2023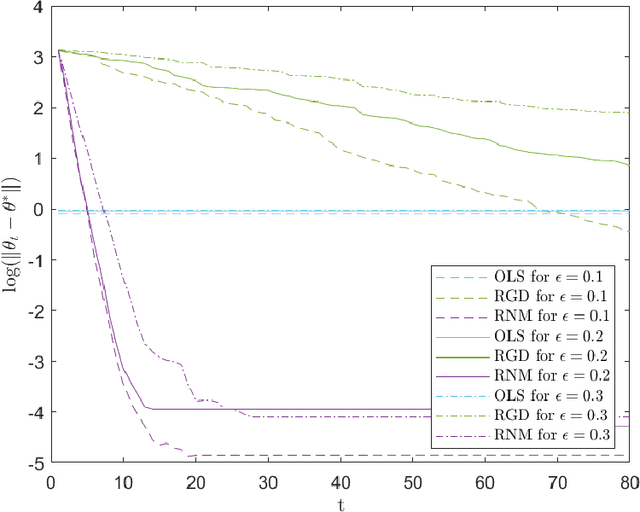

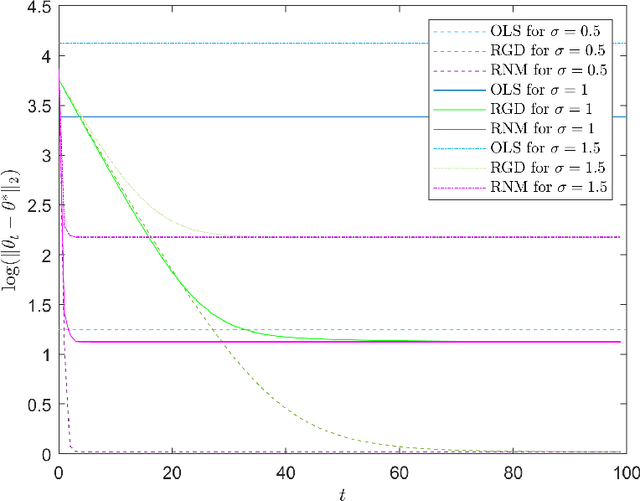
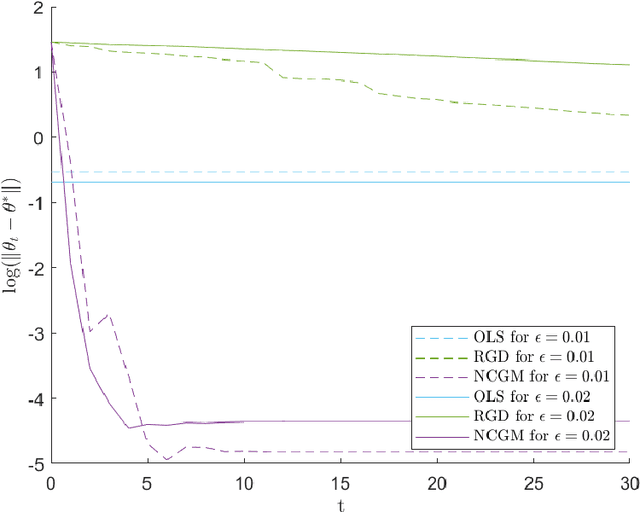
We study a variant of Newton's method for empirical risk minimization, where at each iteration of the optimization algorithm, we replace the gradient and Hessian of the objective function by robust estimators taken from existing literature on robust mean estimation for multivariate data. After proving a general theorem about the convergence of successive iterates to a small ball around the population-level minimizer, we study consequences of our theory in generalized linear models, when data are generated from Huber's epsilon-contamination model and/or heavy-tailed distributions. We also propose an algorithm for obtaining robust Newton directions based on the conjugate gradient method, which may be more appropriate for high-dimensional settings, and provide conjectures about the convergence of the resulting algorithm. Compared to the robust gradient descent algorithm proposed by Prasad et al. (2020), our algorithm enjoys the faster rates of convergence for successive iterates often achieved by second-order algorithms for convex problems, i.e., quadratic convergence in a neighborhood of the optimum, with a stepsize that may be chosen adaptively via backtracking linesearch.