 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Adaptive Temporal-Difference Learning Using An Ensemble of Gaussian Processes
Paper and Code
Dec 01, 2021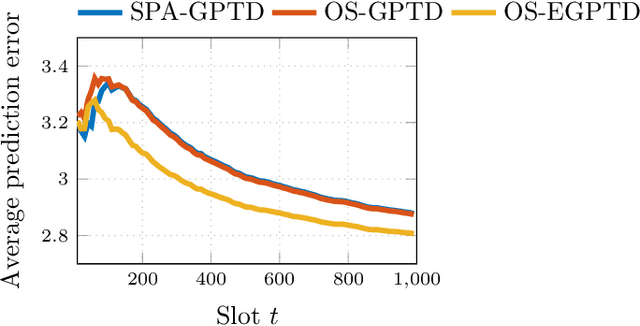
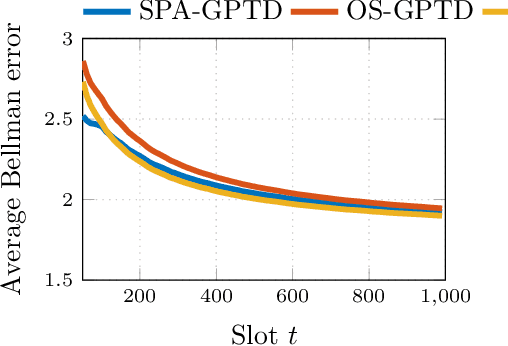
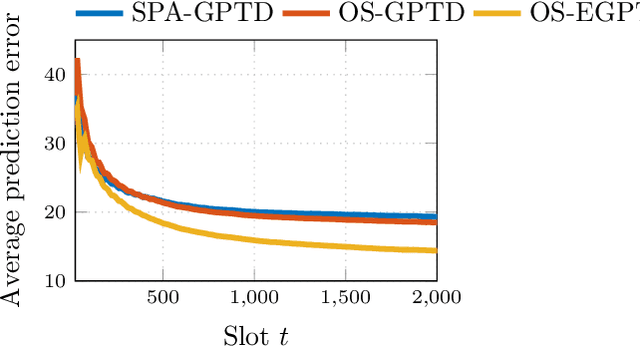
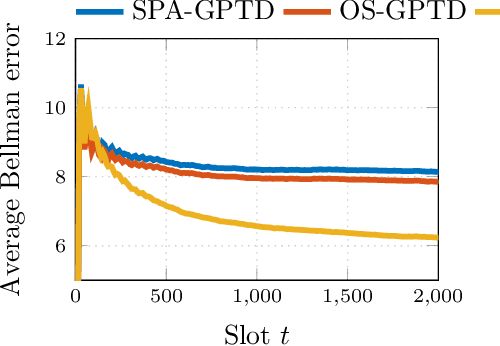
Value function approximation is a crucial module for policy evaluation in reinforcement learning when the state space is large or continuous. The present paper takes a generative perspective on policy evaluation via temporal-difference (TD) learning, where a Gaussian process (GP) prior is presumed on the sought value function, and instantaneous rewards are probabilistically generated based on value function evaluations at two consecutive states. Capitalizing on a random feature-based approximant of the GP prior, an online scalable (OS) approach, termed {OS-GPTD}, is developed to estimate the value function for a given policy by observing a sequence of state-reward pairs. To benchmark the performance of OS-GPTD even in an adversarial setting, where the modeling assumptions are violated, complementary worst-case analyses are performed by upper-bounding the cumulative Bellman error as well as the long-term reward prediction error, relative to their counterparts from a fixed value function estimator with the entire state-reward trajectory in hindsight. Moreover, to alleviate the limited expressiveness associated with a single fixed kernel, a weighted ensemble (E) of GP priors is employed to yield an alternative scheme, termed OS-EGPTD, that can jointly infer the value function, and select interactively the EGP kernel on-the-fly. Finally, performances of the novel OS-(E)GPTD schemes are evaluated on two benchmark problems.