 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk-Sensitive Markov Decision Processes with Combined Metrics of Mean and Variance
Paper and Code
Aug 09, 2020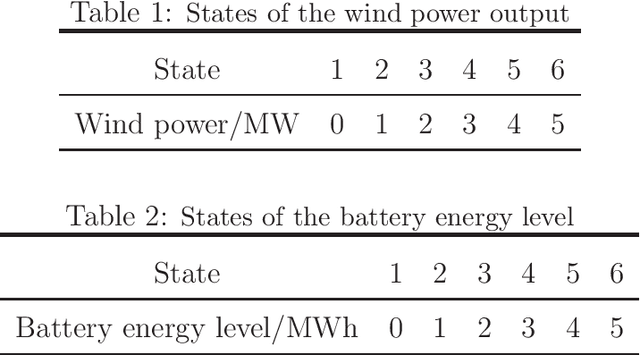
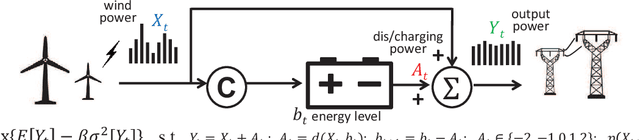
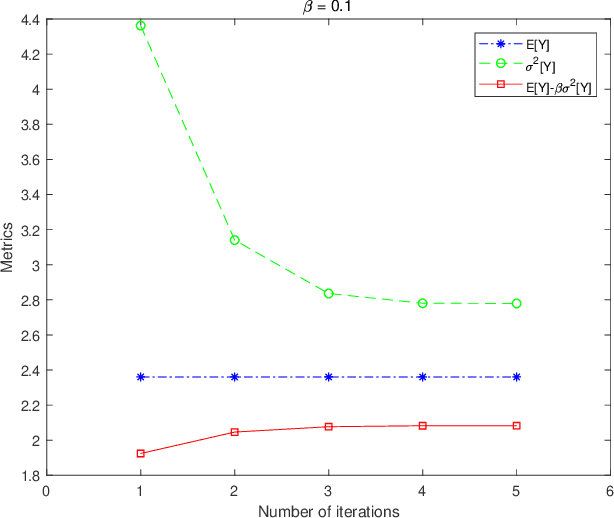

This paper investigates the optimization problem of an infinite stage discrete time Markov decision process (MDP) with a long-run average metric considering both mean and variance of rewards together. Such performance metric is important since the mean indicates average returns and the variance indicates risk or fairness. However, the variance metric couples the rewards at all stages, the traditional dynamic programming is inapplicable as the principle of time consistency fails. We study this problem from a new perspective called the sensitivity-based optimization theory. A performance difference formula is derived and it can quantify the difference of the mean-variance combined metrics of MDPs under any two different policies. The difference formula can be utilized to generate new policies with strictly improved mean-variance performance. A necessary condition of the optimal policy and the optimality of deterministic policies are derived. We further develop an iterative algorithm with a form of policy iteration, which is proved to converge to local optima both in the mixed and randomized policy space. Specially, when the mean reward is constant in policies, the algorithm is guaranteed to converge to the global optimum. Finally, we apply our approach to study the fluctuation reduction of wind power in an energy storage system, which demonstrates the potential applicability of our optimization method.