 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk Minimization in Structured Prediction using Orbit Loss
Paper and Code
Dec 09, 2015
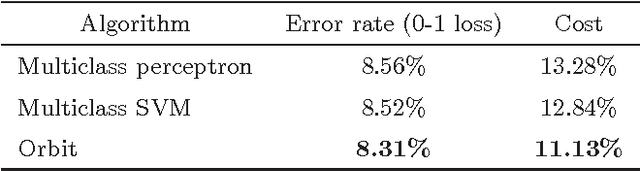


We introduce a new surrogate loss function called orbit loss in the structured prediction framework, which has good theoretical and practical advantages. While the orbit loss is not convex, it has a simple analytical gradient and a simple perceptron-like learning rule. We analyze the new loss theoretically and state a PAC-Bayesian generalization bound. We also prove that the new loss is consistent in the strong sense; namely, the risk achieved by the set of the trained parameters approaches the infimum risk achievable by any linear decoder over the given features. Methods that are aimed at risk minimization, such as the structured ramp loss, the structured probit loss and the direct loss minimization require at least two inference operations per training iteration. In this sense, the orbit loss is more efficient as it requires only one inference operation per training iteration, while yields similar performance. We conclude the paper with an empirical comparison of the proposed loss function to the structured hinge loss, the structured ramp loss, the structured probit loss and the direct loss minimization method on several benchmark datasets and tasks.