 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRicher Countries and Richer Representations
Paper and Code

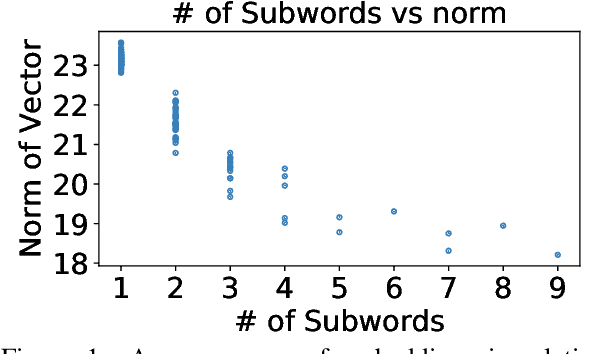
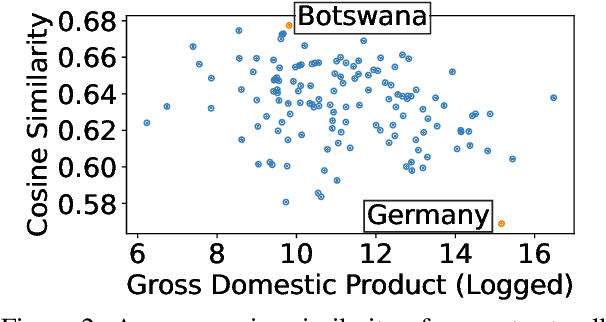
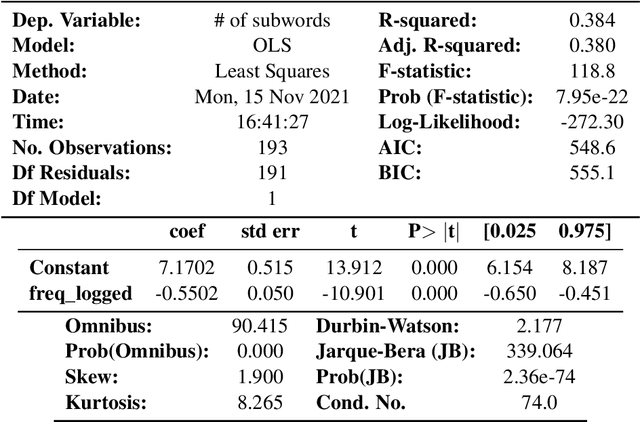
We examine whether some countries are more richly represented in embedding space than others. We find that countries whose names occur with low frequency in training corpora are more likely to be tokenized into subwords, are less semantically distinct in embedding space, and are less likely to be correctly predicted: e.g., Ghana (the correct answer and in-vocabulary) is not predicted for, "The country producing the most cocoa is [MASK].". Although these performance discrepancies and representational harms are due to frequency, we find that frequency is highly correlated with a country's GDP; thus perpetuating historic power and wealth inequalities. We analyze the effectiveness of mitigation strategies; recommend that researchers report training word frequencies; and recommend future work for the community to define and design representational guarantees.