 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRich Feature Construction for the Optimization-Generalization Dilemma
Paper and Code
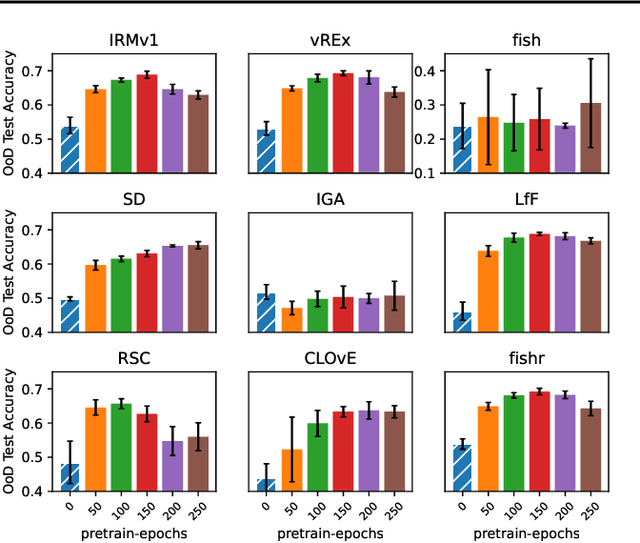
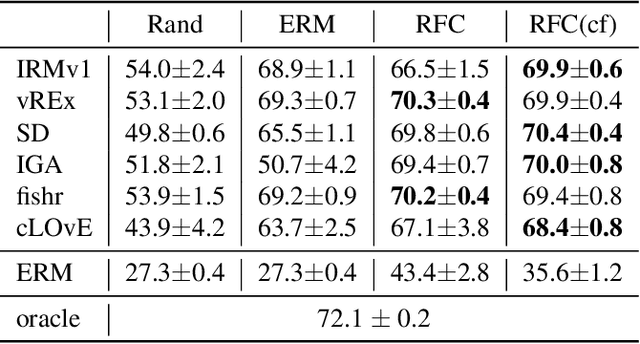
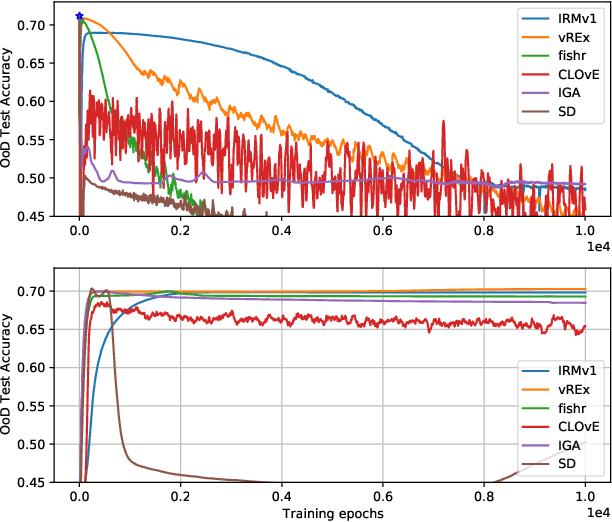
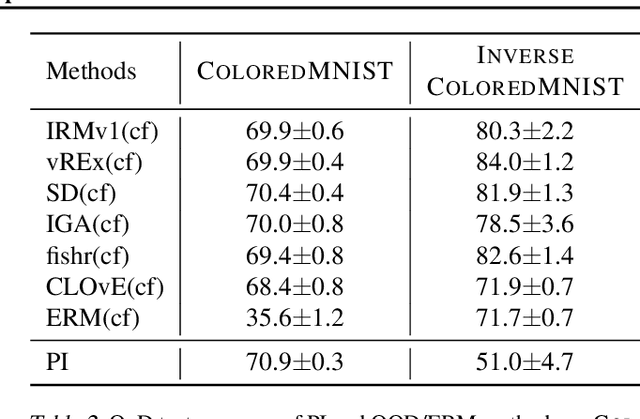
There often is a dilemma between ease of optimization and robust out-of-distribution (OoD) generalization. For instance, many OoD methods rely on penalty terms whose optimization is challenging. They are either too strong to optimize reliably or too weak to achieve their goals. In order to escape this dilemma, we propose to first construct a rich representation (RFC) containing a palette of potentially useful features, ready to be used by even simple models. On the one hand, a rich representation provides a good initialization for the optimizer. On the other hand, it also provides an inductive bias that helps OoD generalization. RFC is constructed in a succession of training episodes. During each step of the discovery phase, we craft a multi-objective optimization criterion and its associated datasets in a manner that prevents the network from using the features constructed in the previous iterations. During the synthesis phase, we use knowledge distillation to force the network to simultaneously develop all the features identified during the discovery phase. RFC consistently helps six OoD methods achieve top performance on challenging invariant training benchmarks, ColoredMNIST (Arjovsky et al., 2020). Furthermore, on the realistic Camelyon17 task, our method helps both OoD and ERM methods outperform earlier compatable results by at least $5\%$, reduce standard deviation by at least $4.1\%$, and makes hyperparameter tuning and model selection more reliable.