Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgerFerns: An Implementation of the Random Ferns Method for General-Purpose Machine Learning
Paper and Code
Nov 14, 2014


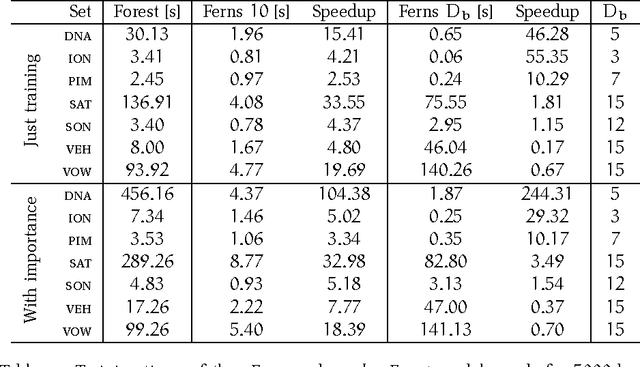
In this paper I present an extended implementation of the Random ferns algorithm contained in the R package rFerns. It differs from the original by the ability of consuming categorical and numerical attributes instead of only binary ones. Also, instead of using simple attribute subspace ensemble it employs bagging and thus produce error approximation and variable importance measure modelled after Random forest algorithm. I also present benchmarks' results which show that although Random ferns' accuracy is mostly smaller than achieved by Random forest, its speed and good quality of importance measure it provides make rFerns a reasonable choice for a specific applications.
* Journal of Statistical Software, 61(10), 1-13
View paper on