 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Relabelling for combined Reinforcement and Imitation Learning on sparse-reward tasks
Paper and Code
Jan 11, 2022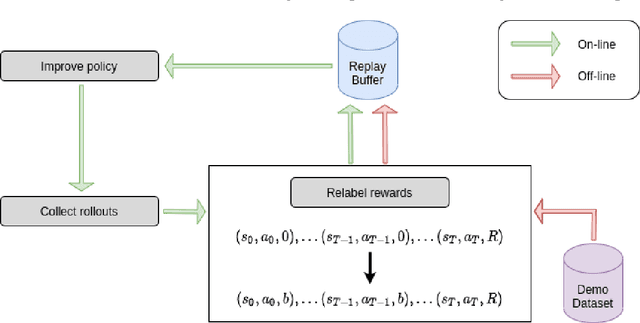


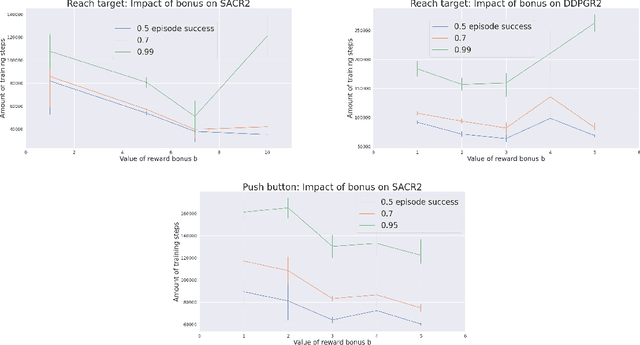
During recent years, deep reinforcement learning (DRL) has made successful incursions into complex decision-making applications such as robotics, autonomous driving or video games. In the search for more sample-efficient algorithms, a promising direction is to leverage as much external off-policy data as possible. One staple of this data-driven approach is to learn from expert demonstrations. In the past, multiple ideas have been proposed to make good use of the demonstrations added to the replay buffer, such as pretraining on demonstrations only or minimizing additional cost functions. We present a new method, able to leverage demonstrations and episodes collected online in any sparse-reward environment with any off-policy algorithm. Our method is based on a reward bonus given to demonstrations and successful episodes, encouraging expert imitation and self-imitation. First, we give a reward bonus to the transitions coming from demonstrations to encourage the agent to match the demonstrated behaviour. Then, upon collecting a successful episode, we relabel its transitions with the same bonus before adding them to the replay buffer, encouraging the agent to also match its previous successes. Our experiments focus on manipulation robotics, specifically on three tasks for a 6 degrees-of-freedom robotic arm in simulation. We show that our method based on reward relabeling improves the performance of the base algorithm (SAC and DDPG) on these tasks, even in the absence of demonstrations. Furthermore, integrating into our method two improvements from previous works allows our approach to outperform all baselines.