 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Open-Domain Question Answering Pipeline
Paper and Code
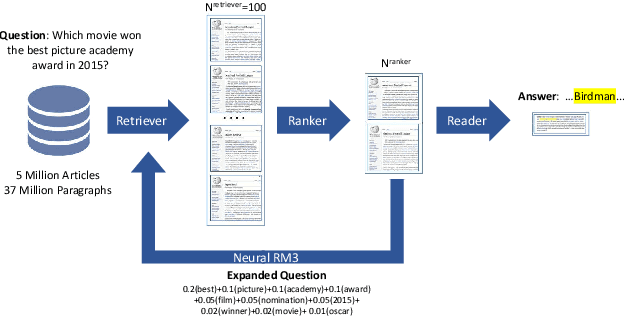
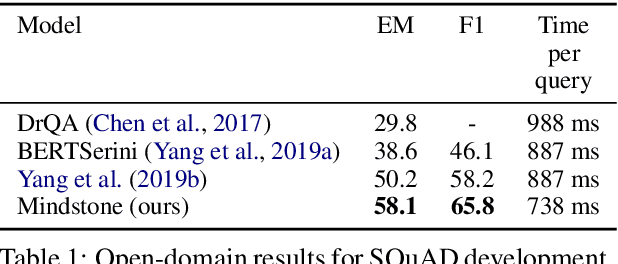
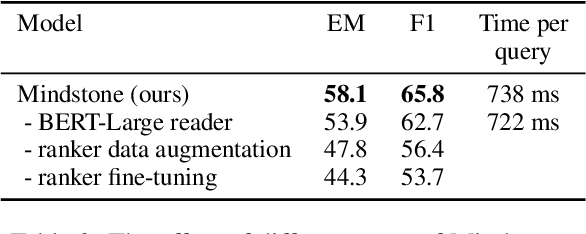

Open-domain question answering (QA) is the tasl of identifying answers to natural questions from a large corpus of documents. The typical open-domain QA system starts with information retrieval to select a subset of documents from the corpus, which are then processed by a machine reader to select the answer spans. This paper describes Mindstone, an open-domain QA system that consists of a new multi-stage pipeline that employs a traditional BM25-based information retriever, RM3-based neural relevance feedback, neural ranker, and a machine reading comprehension stage. This paper establishes a new baseline for end-to-end performance on question answering for Wikipedia/SQuAD dataset (EM=58.1, F1=65.8), with substantial gains over the previous state of the art (Yang et al., 2019b). We also show how the new pipeline enables the use of low-resolution labels, and can be easily tuned to meet various timing requirements.