 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Challenges in Data-to-Text Generation with Fact Grounding
Paper and Code

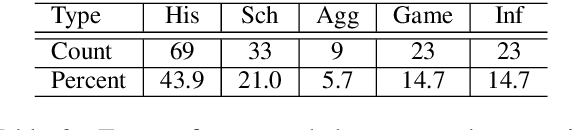
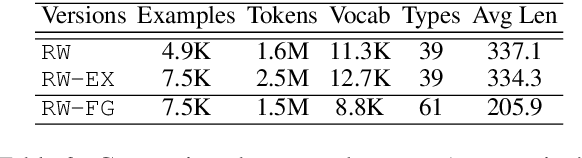
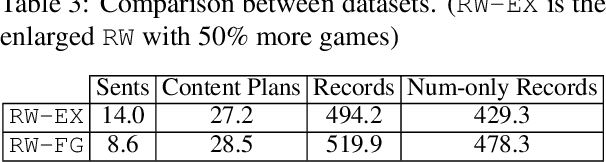
Data-to-text generation models face challenges in ensuring data fidelity by referring to the correct input source. To inspire studies in this area, Wiseman et al. (2017) introduced the RotoWire corpus on generating NBA game summaries from the box- and line-score tables. However, limited attempts have been made in this direction and the challenges remain. We observe a prominent bottleneck in the corpus where only about 60% of the summary contents can be grounded to the boxscore records. Such information deficiency tends to misguide a conditioned language model to produce unconditioned random facts and thus leads to factual hallucinations. In this work, we restore the information balance and revamp this task to focus on fact-grounded data-to-text generation. We introduce a purified and larger-scale dataset, RotoWire-FG (Fact-Grounding), with 50% more data from the year 2017-19 and enriched input tables, hoping to attract more research focuses in this direction. Moreover, we achieve improved data fidelity over the state-of-the-art models by integrating a new form of table reconstruction as an auxiliary task to boost the generation quality.