 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Parameter Counting in Deep Models: Effective Dimensionality Revisited
Paper and Code
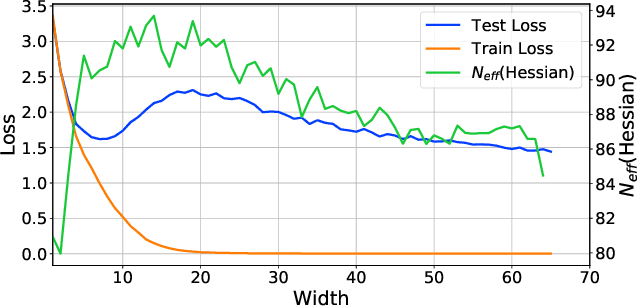
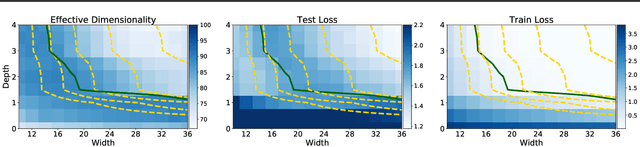
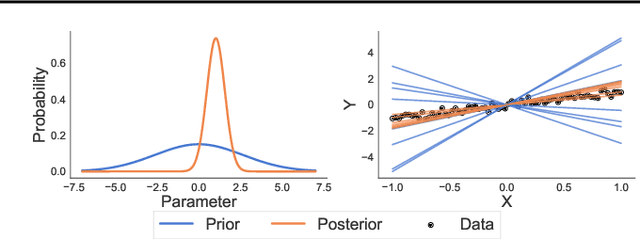
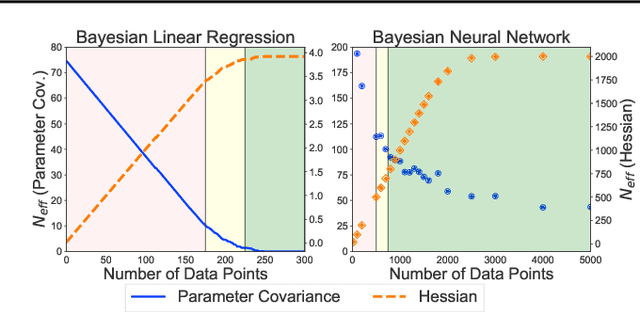
Neural networks appear to have mysterious generalization properties when using parameter counting as a proxy for complexity. Indeed, neural networks often have many more parameters than there are data points, yet still provide good generalization performance. Moreover, when we measure generalization as a function of parameters, we see double descent behaviour, where the test error decreases, increases, and then again decreases. We show that many of these properties become understandable when viewed through the lens of effective dimensionality, which measures the dimensionality of the parameter space determined by the data. We relate effective dimensionality to posterior contraction in Bayesian deep learning, model selection, double descent, and functional diversity in loss surfaces, leading to a richer understanding of the interplay between parameters and functions in deep models.