 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking and Scaling Up Graph Contrastive Learning: An Extremely Efficient Approach with Group Discrimination
Paper and Code
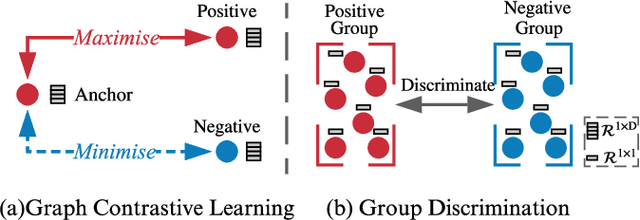
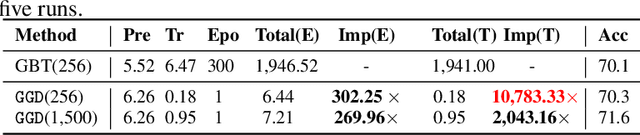
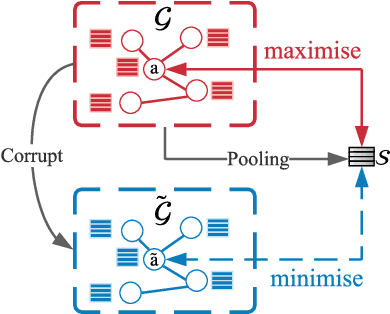
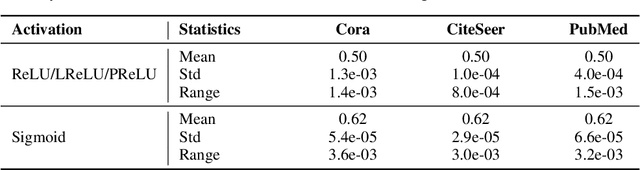
Graph contrastive learning (GCL) alleviates the heavy reliance on label information for graph representation learning (GRL) via self-supervised learning schemes. The core idea is to learn by maximising mutual information for similar instances, which requires similarity computation between two node instances. However, this operation can be computationally expensive. For example, the time complexity of two commonly adopted contrastive loss functions (i.e., InfoNCE and JSD estimator) for a node is $O(ND)$ and $O(D)$, respectively, where $N$ is the number of nodes, and $D$ is the embedding dimension. Additionally, GCL normally requires a large number of training epochs to be well-trained on large-scale datasets. Inspired by an observation of a technical defect (i.e., inappropriate usage of Sigmoid function) commonly used in two representative GCL works, DGI and MVGRL, we revisit GCL and introduce a new learning paradigm for self-supervised GRL, namely, Group Discrimination (GD), and propose a novel GD-based method called Graph Group Discrimination (GGD). Instead of similarity computation, GGD directly discriminates two groups of summarised node instances with a simple binary cross-entropy loss. As such, GGD only requires $O(1)$ for loss computation of a node. In addition, GGD requires much fewer training epochs to obtain competitive performance compared with GCL methods on large-scale datasets. These two advantages endow GGD with the very efficient property. Extensive experiments show that GGD outperforms state-of-the-art self-supervised methods on 8 datasets. In particular, GGD can be trained in 0.18 seconds (6.44 seconds including data preprocessing) on ogbn-arxiv, which is orders of magnitude (10,000+ faster than GCL baselines} while consuming much less memory. Trained with 9 hours on ogbn-papers100M with billion edges, GGD outperforms its GCL counterparts in both accuracy and efficiency.