 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRESSA: Repair Sparse Vision-Language Models via Sparse Cross-Modality Adaptation
Paper and Code
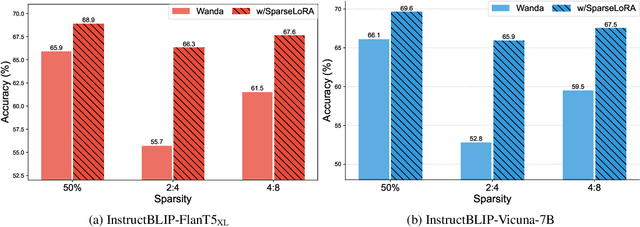



Vision-Language Models (VLMs), integrating diverse information from multiple modalities, have shown remarkable success across various tasks. However, deploying VLMs, comprising large-scale vision and language models poses challenges in resource-constrained scenarios. While pruning followed by finetuning offers a potential solution to maintain performance with smaller model sizes, its application to VLMs remains relatively unexplored, presenting two main questions: how to distribute sparsity across different modality-specific models, and how to repair the performance of pruned sparse VLMs. To answer the first question, we conducted preliminary studies on VLM pruning and found that pruning vision models and language models with the same sparsity ratios contribute to nearly optimal performance. For the second question, unlike finetuning unimodal sparse models, sparse VLMs involve cross-modality interactions, requiring specialized techniques for post-pruning performance repair. Moreover, while parameter-efficient LoRA finetuning has been proposed to repair the performance of sparse models, a significant challenge of weights merging arises due to the incompatibility of dense LoRA modules with sparse models that destroy the sparsity of pruned models. To tackle these challenges, we propose to Repair Sparse Vision-Language Models via Sparse Cross-modality Adaptation (RESSA). RESSA utilizes cross-modality finetuning to enhance task-specific performance and facilitate knowledge distillation from original dense models. Additionally, we introduce SparseLoRA, which applies sparsity directly to LoRA weights, enabling seamless integration with sparse models. Our experimental results validate the effectiveness of RESSA, showcasing significant enhancements, such as an 11.3\% improvement under 2:4 sparsity and a remarkable 47.6\% enhancement under unstructured 70\% sparsity.