 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving the Disparate Impact of Uncertainty: Affirmative Action vs. Affirmative Information
Paper and Code
Feb 19, 2021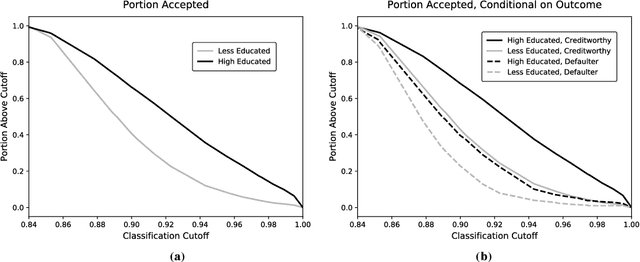
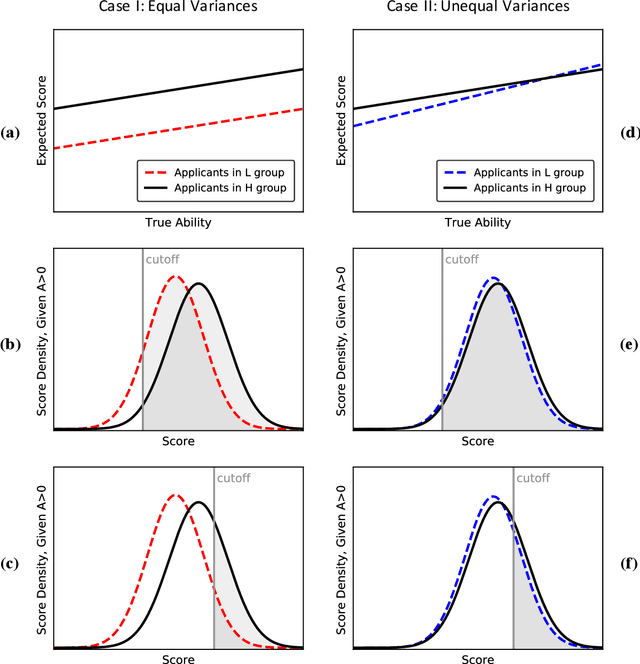
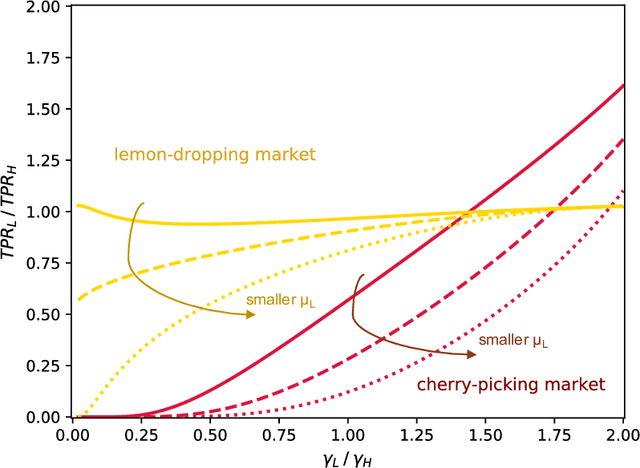
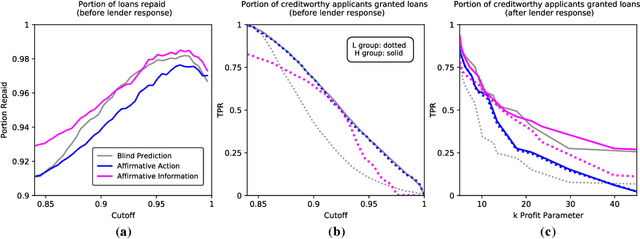
Algorithmic risk assessments hold the promise of greatly advancing accurate decision-making, but in practice, multiple real-world examples have been shown to distribute errors disproportionately across demographic groups. In this paper, we characterize why error disparities arise in the first place. We show that predictive uncertainty often leads classifiers to systematically disadvantage groups with lower-mean outcomes, assigning them smaller true and false positive rates than their higher-mean counterparts. This can occur even when prediction is group-blind. We prove that to avoid these error imbalances, individuals in lower-mean groups must either be over-represented among positive classifications or be assigned more accurate predictions than those in higher-mean groups. We focus on the latter condition as a solution to bridge error rate divides and show that data acquisition for low-mean groups can increase access to opportunity. We call the strategy "affirmative information" and compare it to traditional affirmative action in the classification task of identifying creditworthy borrowers.