 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolvable Designs for Speeding up Distributed Computing
Paper and Code
Aug 14, 2019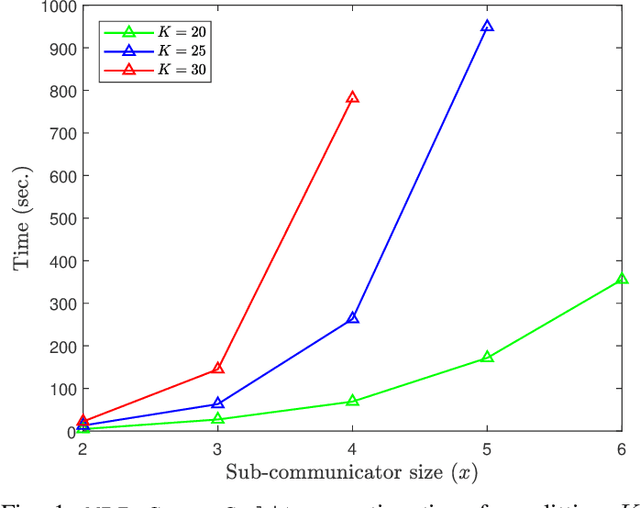

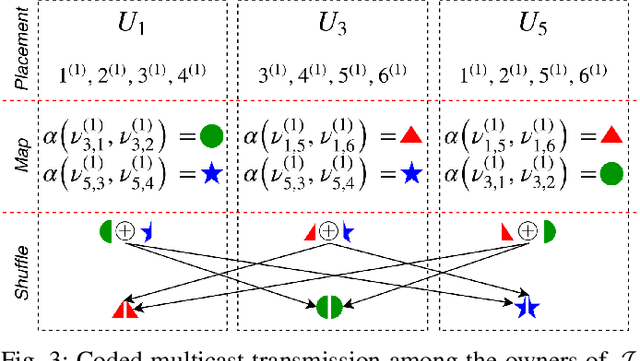

Distributed computing frameworks such as MapReduce are often used to process large computational jobs. They operate by partitioning each job into smaller tasks executed on different servers. The servers also need to exchange intermediate values to complete the computation. Experimental evidence suggests that this so-called Shuffle phase can be a significant part of the overall execution time for several classes of jobs. Prior work has demonstrated a natural tradeoff between computation and communication whereby running redundant copies of jobs can reduce the Shuffle traffic load, thereby leading to reduced overall execution times. For a single job, the main drawback of this approach is that it requires the original job to be split into a number of files that grows exponentially in the system parameters. When extended to multiple jobs (with specific function types), these techniques suffer from a limitation of a similar flavor, i.e., they require an exponentially large number of jobs to be executed. In practical scenarios, these requirements can significantly reduce the promised gains of the method. In this work, we show that a class of combinatorial structures called resolvable designs can be used to develop efficient coded distributed computing schemes for both the single and multiple job scenarios considered in prior work. We present both theoretical analysis and exhaustive experimental results (on Amazon EC2 clusters) that demonstrate the performance advantages of our method. For the single and multiple job cases, we obtain speed-ups of 4.69x (and 2.6x over prior work) and 4.31x over the baseline approach, respectively.