Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresenting Text Chunks
Paper and Code
Jul 06, 1999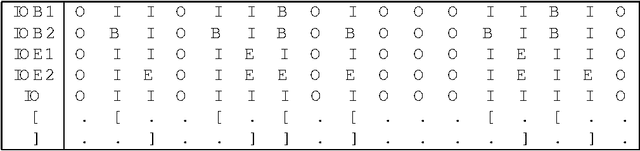

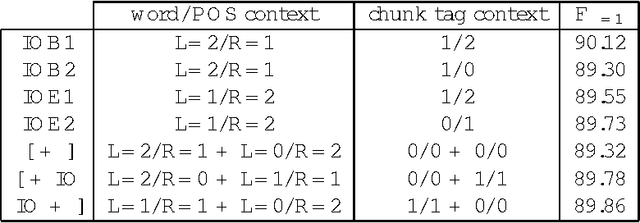

Dividing sentences in chunks of words is a useful preprocessing step for parsing, information extraction and information retrieval. (Ramshaw and Marcus, 1995) have introduced a "convenient" data representation for chunking by converting it to a tagging task. In this paper we will examine seven different data representations for the problem of recognizing noun phrase chunks. We will show that the the data representation choice has a minor influence on chunking performance. However, equipped with the most suitable data representation, our memory-based learning chunker was able to improve the best published chunking results for a standard data set.
* EACL'99, Bergen * 7 pages
View paper on